between clients and brokers

Goldsky is a Web3 developer platform focused on providing real-time and historical blockchain data access. They enable developers to index and stream data from smart contracts and entire chains via API endpoints, Subgraphs, and streaming pipelines, making it easier to build dApps without managing complex infrastructure.
Goldsky has two primary products: subgraph and mirror. Subgraph enables customers to index and query blockchain data in real-time. Mirror is a solution for CDCing blockchain data directly into customer-owned databases so that application data and blockchain data can coexist in the same data stores and be queried together.
As a real-time data streaming company, Goldsky’s engineering stack naturally was built on-top of Apache Kafka. Goldsky uses Kafka as the storage and transport layer for all of the blockchain data that powers their product.
But Goldsky doesn’t use Apache Kafka like most teams do. They treat Kafka as a permanent, historical record of all of the blockchain data that they’ve ever processed. That means that almost all of Goldsky’s topics are configured with infinite retention and topic compaction enabled. In addition, they track many different sources of blockchain data and as a result, have many topics in their cluster (7,000+ topics and 49,000+ partitions before replication).
In other words, Goldsky uses Kafka as a database and they push it hard. They run more than 200 processing jobs and 10,000 consumer clients against their cluster 24/7 and that number grows every week. Unsurprisingly, when we first met Goldsky they were struggling to scale their growing Kafka cluster. They tried multiple different vendors (incurring significant migration effort each time), but ran into both cost and reliability issues with each solution.
“One of our customers churned when our previous Kafka vendor went down right when that customer was giving an investor demo. That was our biggest contract at the time. The dashboard with the number of consumers and kafka error rate was the first thing I used to check every morning.”
– Jeffrey Ling, Goldsky CTO
In addition to all of the reliability problems they were facing, Goldsky was also struggling with costs.
The first source of huge costs for them was due to their partition counts. Most Kafka vendors charge for partitions. For example, in AWS MSK an express.m7g.4xl broker is recommended to host no more than 6000 partitions (including replication). That means that Goldsky’s workload would require: <span class="formula">(41,000 * 3 (replication factor)) / 6000 = 20</span> express.m7g.4xl brokers just to support the number of partitions in their cluster. At <span class="formula">$3.264/broker/hr</span>, their cluster would cost more than half a million dollars a year with zero traffic and zero storage!
It’s not just the partition counts in this cluster that makes it expensive though. The sheer amount of data being stored due to all the topics having infinite retention also makes it very expensive.
The canonical solution to high storage costs in Apache Kafka is to use tiered storage, and that’s what Goldsky did. They enabled tiered storage in all the different Kafka vendors they used, but they found that while the tiered storage implementations did reduce their storage costs, they also dramatically reduced the performance of reading historical data and caused significant reliability problems.
In some cases the poor performance of consuming historical data would lock up the entire cluster and prevent them from producing/consuming recent data. This problem was so acute that the number one obstacle for Goldsky’s migration to WarpStream was the fact that they had to severely throttle the migration to avoid overloading their previous Kafka vendor's clusters tiered storage implementations when copying their historical data into WarpStream.
Goldsky saw a number of cost and performance benefits with their migration to WarpStream. Their total cost of ownership (TCO) with WarpStream is less than 1/10th of what their TCO was with their previous Kafka vendor. Some of these savings came from WarpStream’s reduced licensing costs, but most of them came from WarpStream’s diskless architecture reducing their infrastructure costs.
“We ended up picking WarpStream because we felt that it was the perfect architecture for this specific use case, and was much more cost effective for us due to less data transfer costs, and horizontally scalable Agents.”
– Jeffrey Ling, Goldsky CTO
Goldsky's previous Kafka vendor required them to constantly scale their cluster (vertically or horizontally) as the partition count of the cluster naturally increased over time. With WarpStream, there is no relationship between the number of partitions and the hardware requirements of the cluster. Now Goldsky’s WarpStream cluster auto-scales based solely on the write and read throughput of their workloads.
Goldsky had a lot of problems with the implementation of tiered storage with their previous Kafka vendor. The solution to these performance problems was to overprovision their cluster and hope for the best. With WarpStream these performance problems have disappeared completely and the performance of their workloads remains constant regardless of whether they’re consuming live or historical data.
This is particularly important to Goldsky because the nature of their product means that customers taking a variety of actions can trigger processing jobs to spin up and begin reading large topics in their entirety. These new workloads can spin up at any moment (even in the middle of the night), and Goldsky's previous Kafka vendor required them to keep their cluster always overprovisioned to handle it. With WarpStream, Goldsky can just let the cluster scale itself up automatically in the middle of the night to accommodate the new workload, and then let it scale itself back down when the workload is complete.
Goldsky's previous Kafka vendor generated significant networking costs due to the traffic between clients and brokers. This problem was particularly acute due to the 4x consumer fanout of their workload. With WarpStream, their networking costs dropped to zero as WarpStream zonally aligns traffic between producers, consumers, and the WarpStream Agents. In addition, WarpStream relies on object storage for replication across zones which does not incur any networking costs either.
In addition to the reduced TCO, Goldsky also gained dramatically better reliability with WarpStream.
“The sort of stuff we put our WarpStream cluster through wasn't even an option with our previous solution. It kept crashing due to the scale of our data, specifically the amount of data we wanted to store. WarpStream just worked. I used to be able to tell you exactly how many consumers we had running at any given moment. We tracked it on a giant health dashboard because if it got too high, the whole system would come crashing down. Today I don’t even keep track of how many consumers are running anymore.”
– Jeffrey Ling, Goldsky CTO
Goldsky was one of WarpStream’s earliest customers. When we first met with them their Kafka cluster had <10,000 partitions and 20 TiB of data in tiered storage. Today their WarpStream cluster has 3.7 PiB of stored data, 11,000+ topics, 41,000+ partitions, and is still growing at an impressive rate!
When we first onboarded Goldsky, we told them we were confident that WarpStream would scale up to “several PiBs of stored data” which seemed like more data than anyone could possibly want to store in Kafka at the time. However as Goldsky’s cluster continued to grow, and we encountered more and more customers who needed infinite retention for high volumes of data streams, we realized that a “several PiBs of stored data” wasn’t going to be enough.
At this point you might be asking yourself: “What’s so hard about storing a few PiBs of data? Isn’t the object store doing all the heavy lifting anyways?”. That’s mostly true, but to provide the abstraction of Kafka over an object store, the WarpStream control plane has to store a lot of metadata. Specifically, WarpStream has to track the location of each batch of data in the object store. This means that the amount of metadata tracked by WarpStream is a function of both the number of partitions in the system, as well as the overall retention:
<span class="formula">metadata = O(num_partitions * retention)</span>
This is a gross oversimplification, but the core of the idea is accurate. We realized that if we were going to scale WarpStream to the largest Kafka clusters in the world, we’d have to break this relationship or at least alter its slope.
We decided to redesign WarpStream’s storage engine and metadata store to solve this problem. This would enable us to accommodate even more growth in Goldsky’s cluster, and onboard even larger infinite retention use-cases with high partition counts.
We called the project “Big Clusters” and set to work. The details of the rewrite are beyond the scope of this blog post, but to summarize: WarpStream’s storage engine is a log structured merge tree. We realized that by re-writing our compaction planning algorithms we could dramatically reduce the amount of metadata amplification that our compaction system generated.
We came up with a solution that reduces the metadata amplification by up to 256, but it came with a trade-off: steady-state write amplification from compaction increased from 2x to 4x for some workloads. To solve this, we modified the storage engine to have two different “modes”: “small” clusters and “big” clusters. All clusters start off in “small” mode by default, and a background process running in our control plane analyzes the workload continuously and automatically upgrades the cluster into “big” mode when appropriate.
This gives our customers the best of both worlds: highly optimized workloads remain as efficient as they are today, and only difficult workloads with hundreds of thousands of partitions and many PiBs of storage are upgraded to “big” mode to support their increased growth. Customers never have to think about it, and WarpStream’s control plane makes sure that each cluster is using the most efficient strategy automatically. As an added bonus, the fact that WarpStream hosts the customer’s control plane means we were able to perform this upgrade for all of our customers without involving them. The process was completely transparent to them.
This is what the upgrade from “small” mode to “big” mode looked like for Goldsky’s cluster:
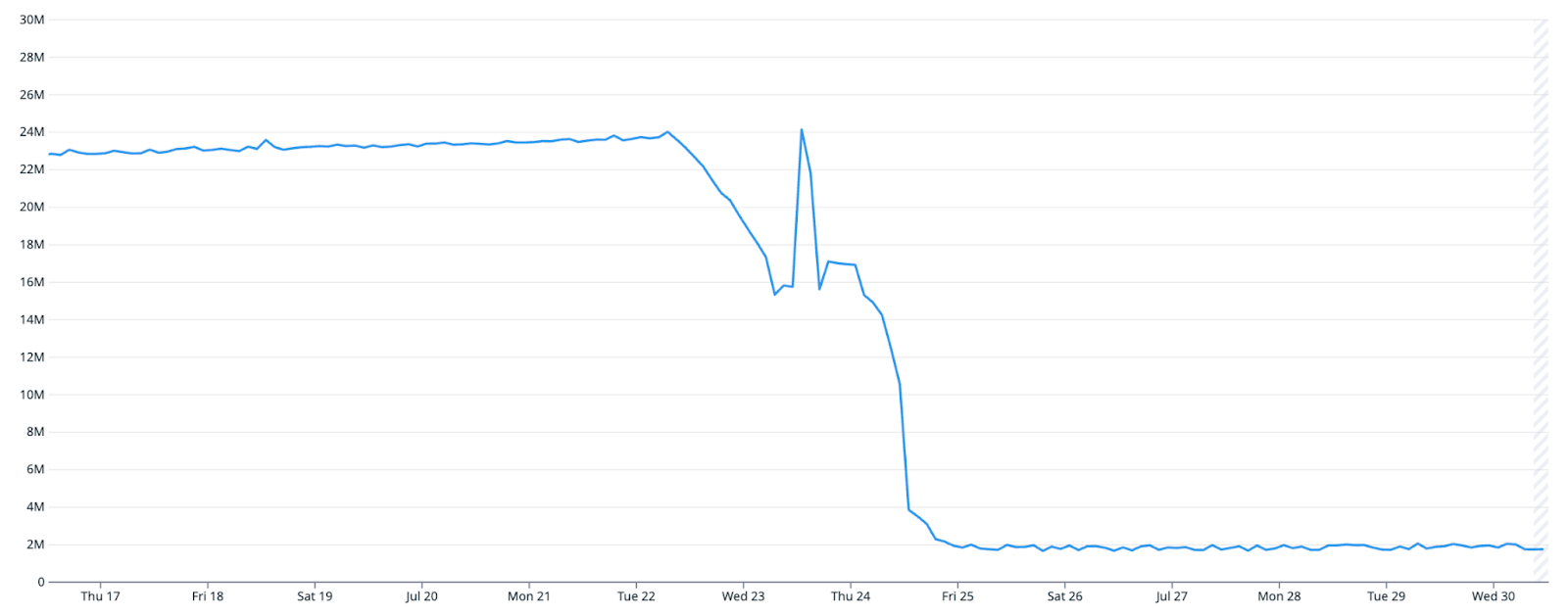
An 85% reduction in the amount of metadata tracked by WarpStream’s control plane!
Paradoxically, Goldsky’s compaction amplification actually decreased when we upgraded their cluster from “small” mode to “big” mode:
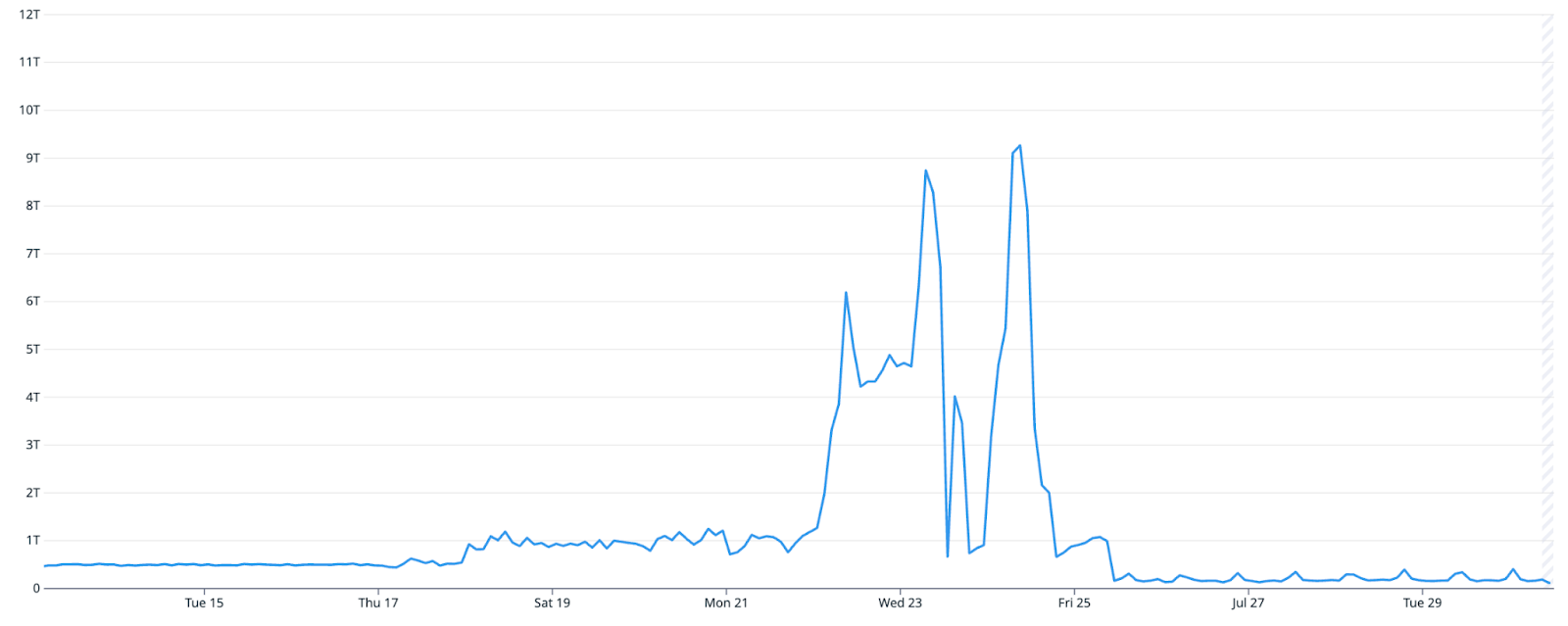
That’s because previously the compaction system was overscheduling compactions to keep the size of the cluster’s metadata under control, but with the new algorithm this was no longer necessary. There’s a reason compaction planning is an NP-hard problem, and the results are not always intuitive!
With the new “big” mode, we’re confident now that a single WarpStream cluster can support up to 100PiBs of data, even when the cluster has hundreds of thousands of topic-partitions.
If you’re struggling with infinite retention, tiered storage, or high costs from a high number of topic-partitions in your Kafka clusters then get in touch with us!
