ShareChat is an India-based, multilingual social media platform that also owns and operates Moj, a short-form video app. Combined, the two services serve personalized content to over 300 million active monthly users across 16 different languages.
Vivek Chandela and Shubham Dhal, Staff Software Engineers at ShareChat, presented a talk (see the appendix for slides and a video of the talk) at Current Bengaluru 2025 about their transition from open-source (OSS) Kafka to WarpStream and best practices for optimizing WarpStream, which we’ve reproduced below.
When most people talk about logs, they’re referencing application logs, but for ShareChat, machine learning far exceeds application logging by a factor of 10x. Why is this the case? Remember all those hundreds of millions of users we just referenced? ShareChat has to return the top-k (the most probable tokens for their models) for ads and personalized content for every user’s feed within milliseconds.
ShareChat utilizes a machine learning (ML) inference and training pipeline that takes in the user request, fetches relevant user and ad-based features, requests model inference, and finally logs the request and features for training. This is a log-and-wait model, as the last step of logging happens asynchronously with training.
Where the data streaming piece comes into play is the inference services. These sit between all these critical services as they’re doing things like requesting a model and getting its response, logging a request and its features, and finally sending a response to personalize a user’s feed.
ShareChat leverages a Kafka-compatible queue to power those inference services, which are fed into Apache Spark to stream (unstructured) data into a Delta Lake. Spark enters the picture again to process it (making it structured), and finally, the data is merged and exported to cloud storage and analytics tables.
.png)
.png)
Two factors made ShareChat look at Kafka alternatives like WarpStream: ShareChat’s highly elastic workloads and steep inter-AZ networking fees, two areas that are common pain points for Kafka implementations.
Depending on the time of the day, ShareChat’s workload for its ads platform can be as low as 20 MiB/s to as high as 320 MiB/s in compressed Produce throughput. This is because, like most social platforms, usage starts climbing in the morning and continues that upward trajectory until it peaks in the evening and then has a sharp drop.
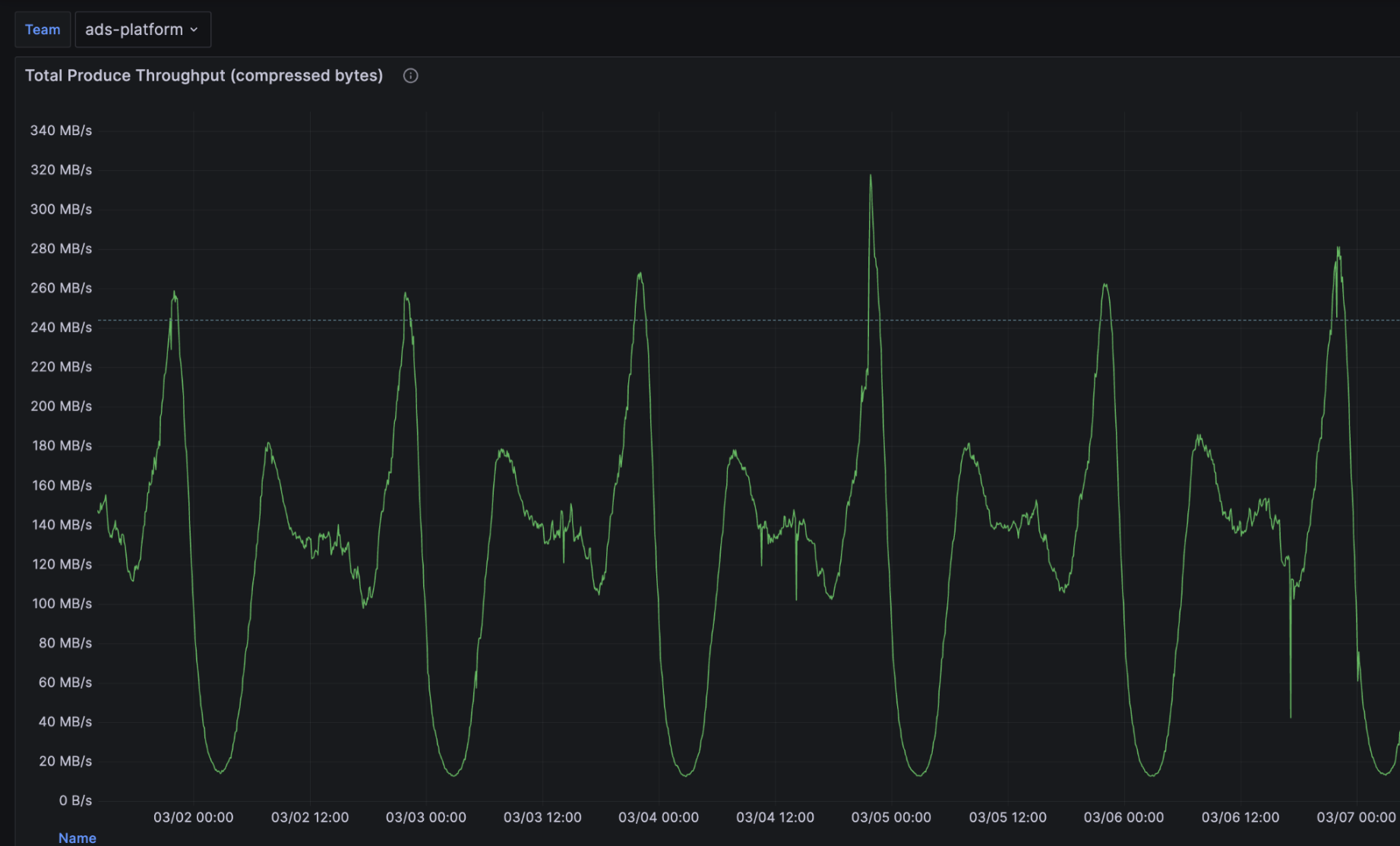
Since OSS Kafka is stateful, ShareChat ran into the following problems with these highly elastic workloads:
Because WarpStream has a stateless or diskless architecture, all those operational issues tied to auto-scaling and partition rebalancing became distant memories. We’ve covered how we handle auto-scaling in a prior blog, but to summarize: Agents (WarpStream’s equivalent of Kafka brokers) auto-scale based on CPU usage; more Agents are automatically added when CPU usage is high and taken away when it’s low. Agents can be customized to scale up and down based on a specific CPU threshold.
“[With WarpStream] our producers and consumers [auto-scale] independently. We have a very simple solution. There is no need for any dedicated team [like with a stateful platform]. There is no need for any local disks. There are very few things that can go wrong when you have a stateless solution. Here, there is no concept of leader election, rebalancing of partitions, and all those things. The metadata store [a virtual cluster] takes care of all those things,” noted Dhal.
As we noted in our original launch blog, “Kafka is dead, long live Kafka”, inter-AZ networking costs can easily make up the vast majority of Kafka infrastructure costs. ShareChat reinforced this, noting that for every leader, if you have a replication factor of 3, you’ll still pay inter-AZ costs for two-thirds of the data as you’re sending it to leader partitions in other zones.
WarpStream gets around this as its Agents are zone-aware, meaning that producers and clients are always aligned in the same zone, and object storage acts as the storage, network, and replication layer.
ShareChat wanted to truly test these claims and compare what WarpStream costs to run vs. single-AZ and multi-AZ Kafka. Before we get into the table with the cost differences, it’s helpful to know the compressed throughput ShareChat used for their tests:
You can see the cost (in USD per day) of this test’s workload in the table below.
According to their tests and the table above, we can see that WarpStream saved ShareChat 58-60% compared to multi-AZ Kafka and 21-27% compared to single-AZ Kafka.
These numbers are very similar to what you would expect if you used WarpStream’s pricing calculator to compare WarpStream vs. Kafka with both fetch from follower and tiered storage enabled.
“There are a lot of blogs that you can read [about optimizing] Kafka to the brim [like using fetch from follower], and they’re like ‘you’ll save this and there’s no added efficiencies’, but there’s still a good 20 to 25 percent [in savings] here,” said Chandela.
Since any WarpStream Agent can act as the “leader” for any topic, commit offsets for any consumer group, or act as the coordinator for the cluster, ShareChat was able to do a zero-ops deployment with no custom tooling, scripts, or <span class="codeinline">StatefulSets</span>.
They used Kubernetes (K8s), and each BU (Business Unit) has a separate WarpStream virtual cluster (metadata store) for logical separation. All Agents in a cluster share a common K8s namespace. Separate deployments are done for Agents in each zone of the K8s cluster, so they scale independently of Agents in other zones.
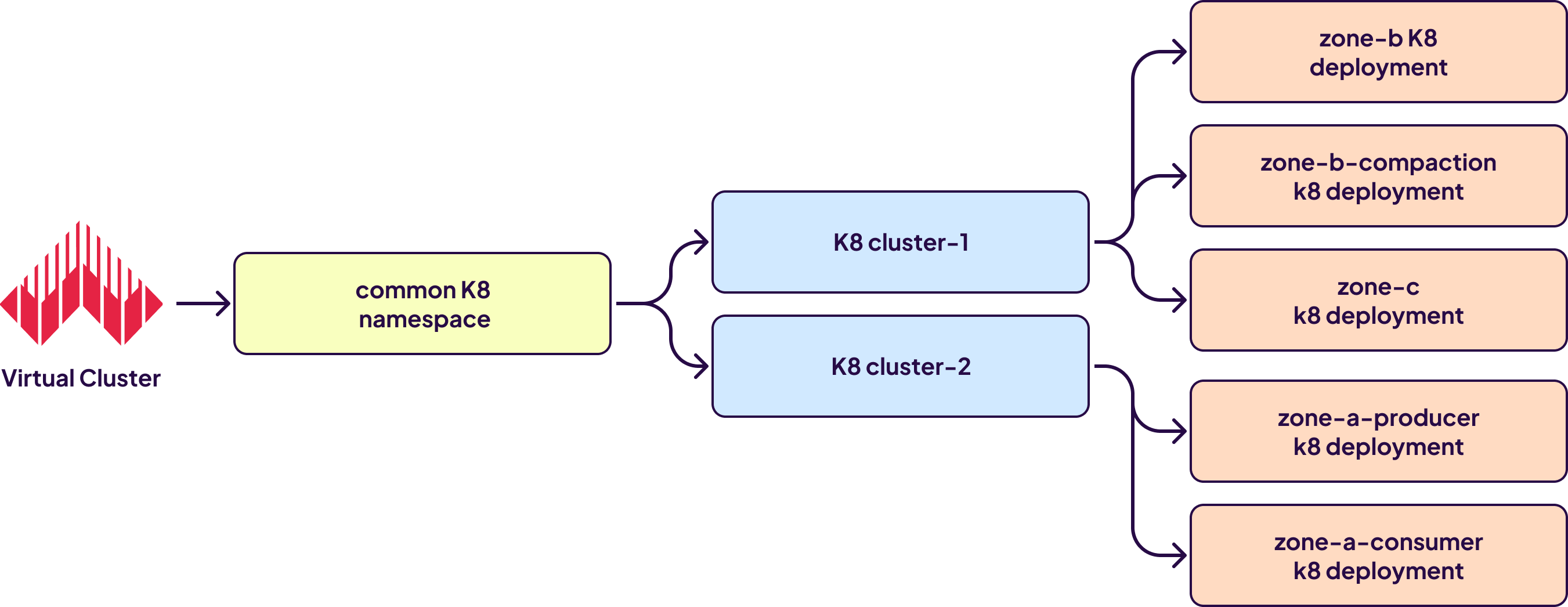
“Because everything is virtualized, we don’t care as much. There's no concept like [Kafka] clusters to manage or things to do – they’re all stateless,” said Dhal.
Since WarpStream uses object storage like S3 as its diskless storage layer, inevitably, two questions come up: what’s the latency, and, while S3 is much cheaper for storage than local disks, what kind of costs can users expect from all the PUTs and GETs to S3?
Regarding latency, ShareChat confirmed they achieved a Produce latency of around 400ms and an E2E producer-to-consumer latency of 1 second. Could that be classified as “too high”?
“For our use case, which is mostly for ML logging, we do not care as much [about latency],” said Dhal.
Chandela reinforced this from a strategic perspective, noting, “As a company, what you should ask yourself is, ‘Do you understand your latency [needs]?’ Like, low latency and all, is pretty cool, but do you really require that? If you don’t, WarpStream comes into the picture and is something you can definitely try.”
While WarpStream eliminates inter-AZ costs, what about S3-related costs for things like PUTs and GETs? WarpStream uses a distributed memory-mapped file (mmap) that allows it to batch data, which reduces the frequency and cost of S3 operations. We covered the benefits of this mmap approach in a prior blog, which is summarized below.
As you can see above and in previous sections, WarpStream already has a lot built into its architecture to reduce costs and operations, and keep things optimal by default, but every business and use case is unique, so ShareChat shared some best practices or optimizations that WarpStream users may find helpful.
ShareChat recommends leveraging Agent roles, which allow you to run different services on different Agents. Agent roles can be configured with the <span class="codeinline">-roles</span> command line flag or the <span class="codeinline">WARPSTREAM_AGENT_ROLES</span> environment variable. Below, you can see how ShareChat splits services across roles.
They run on-spot instances instead of on-demand instances for their Agents to save on instance costs, as the former don’t have fixed hourly rates or long-term commitments, and you’re bidding on spare or unused capacity. However, make sure you know your use case. For ShareChat, spot instances make sense as their workloads are flexible, batch-oriented, and not latency sensitive.
When it comes to Agent size and count, a small number of large Agents can be more efficient than a large number of small Agents:
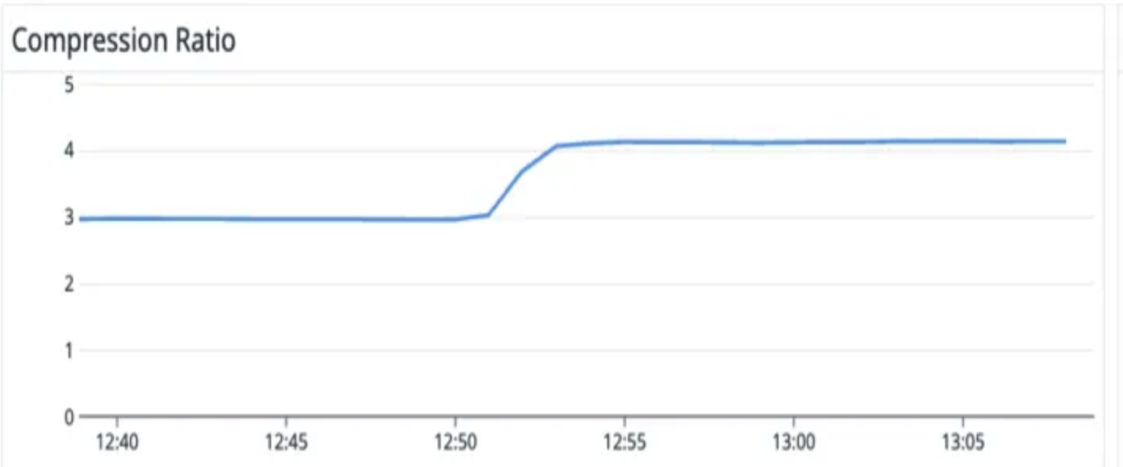
The <span class="codeinline">-storageCompression</span> (<span class="codeinline">WARPSTREAM_STORAGE_COMPRESSION</span>) setting in WarpStream uses LZ4 compression by default (it will update to ZSTD in the future), and ShareChat uses ZSTD. They further tuned ZSTD via the <span class="codeinline">WARPSTREAM_ZSTD_COMPRESSION_LEVEL</span> variable, which has values of -7 (fastest) to 22 (slowest in speed, but the best compression ratio).
After making those changes, they saw a 33% increase in compression ratio and a 35% cost reduction.
ZSTD used slightly more CPU, but it resulted in better compression, cost savings, and less network saturation.
For Producer Agents, larger batches, e.g., doubling batch size, are more cost-efficient than smaller batches, as they can cut PUT requests in half. Small batches increase:
How do you increase batch size? There are two options:
The next question is: How do I know if my batch size is optimal? Check the p99 uncompressed size of L0 files. ShareChat offered these guidelines:
In ShareChat’s case, they went with option No. 2, increasing the <span class="codeinline">batchMaxSizeBytes</span> to 16 MB, which cut PUT requests in half while only increasing PUT bytes latency by 141ms and Produce latency by 70ms – a very reasonable tradeoff in latency for additional cost savings.
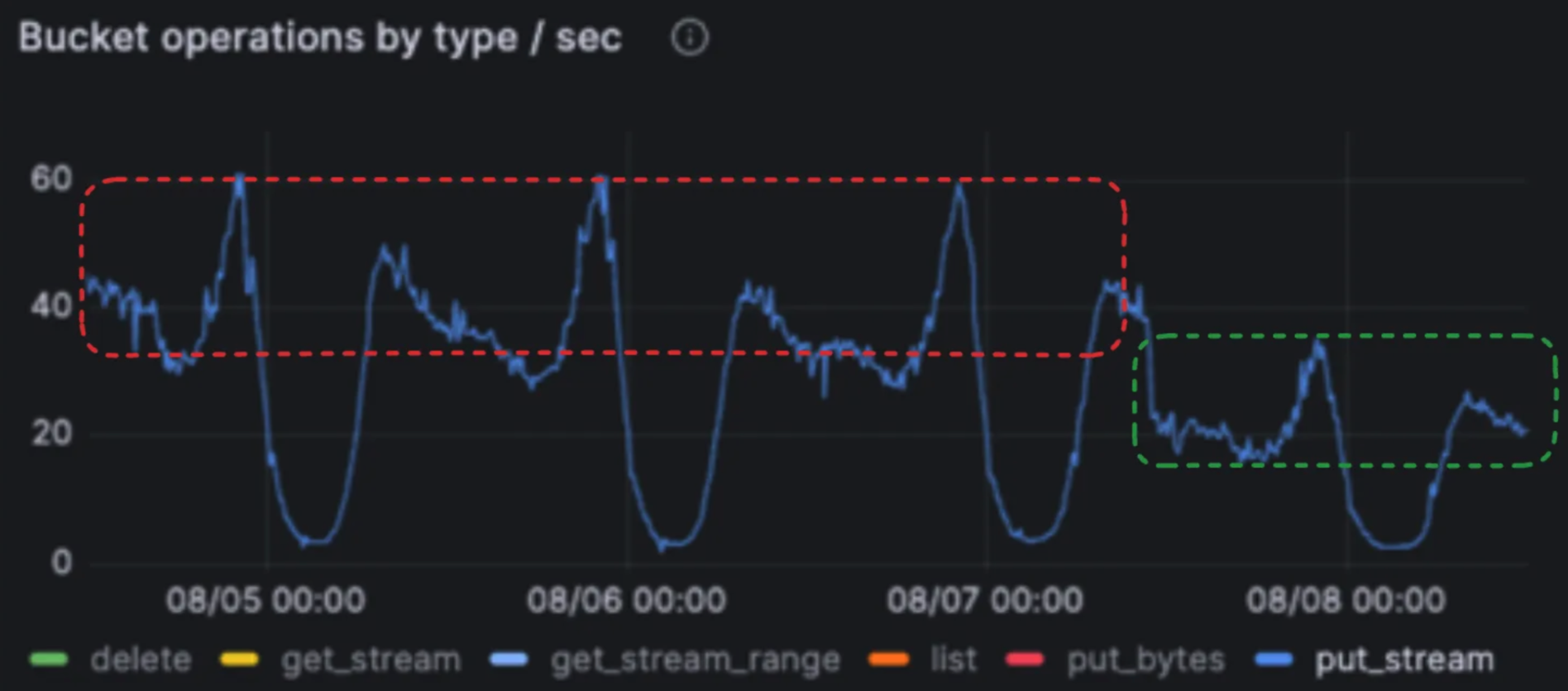
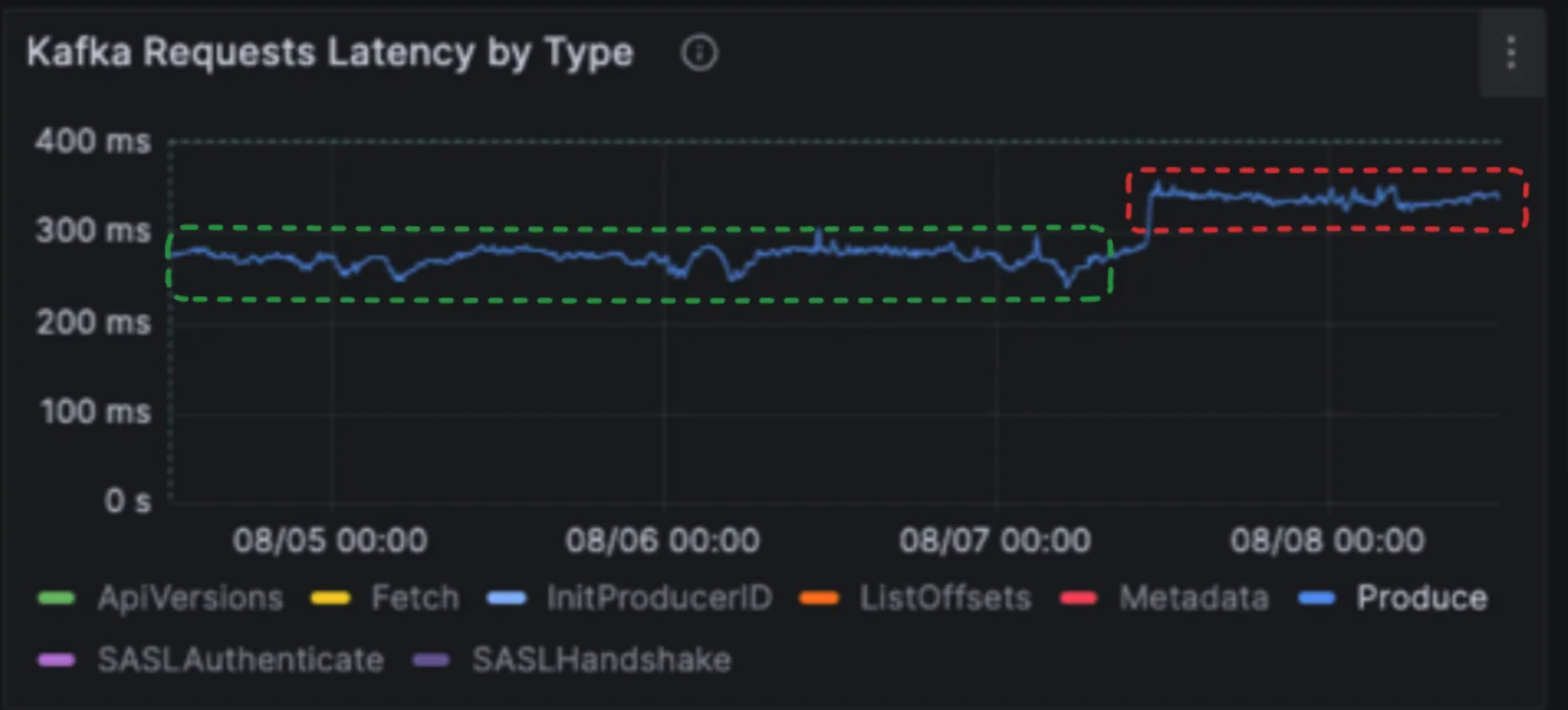
For Jobs Agents, ShareChat noted they need to be throughput optimized, so they can run hotter than other agents. For example, instead of using a CPU usage target of 50%, they can run at 70%. They should be network optimized so they can saturate the CPU before the network interface, given they’re running in the background and doing a lot of compactions.
To eliminate inter-AZ costs, append <span class="codeinline">warpstream_az=<your-az></span> to the <span class="codeinline">ClientID</span> for both producer and consumer. If you forget to do this, no worries: WarpStream Diagnostics will flag this for you in the Console.
Use the <span class="codeinline">warpstream_proxy_target</span> (see docs) to route individual Kafka clients to Agents that are running specific roles, e.g.:
Set <span class="codeinline">RECORD_RETRIES=3</span> and use compression. This will allow the producer to attempt to resend a failed record to the WarpStream Agents up to three times if it encounters an error. Pairing it with compression will improve throughput and reduce network traffic.
The <span class="codeinline">metaDataMaxAge</span> sets the maximum age for the client's cached metadata. If you want to ensure the metadata is refreshed more frequently, you can set <span class="codeinline">metaDataMaxAge</span> to 60 seconds in the client.
You can also leverage a sticky partitioner instead of a round robin partitioner to assign records to the same partition until a batch is sent, then increment to the next partition for the subsequent batch to reduce Produce requests and improve latency.
WarpStream has a default value of 250ms for <span class="codeinline">WARPSTREAM_BATCH_TIMEOUT</span> (we referenced this in the Agent Optimization section), but it can go as low as 50ms. This will decrease latency, but it increases costs as more files have to be created in the object storage, and you have more PUT costs. You have to assess the tradeoff between latency and infrastructure cost. It doesn’t impact durability as Produce requests are never acknowledged to the client before data is persisted to object storage.
If you’re on any of the WarpStream tiers above Dev, you have the option to decrease control plane latency.
You can leverage S3 Express One Zone (S3EOZ) instead of S3 Standard if you’re using AWS. This will decrease latency by 3x and only increase the total cost of ownership (TCO) by about 15%.
Even though S3EOZ storage is 8x more expensive than S3 standard, since WarpStream compacts the data into S3 standard within seconds, the effective storage rate remains $0.02 Gi/B – the slightly higher costs come not from storage, but increased PUTs and data transfer. See our S3EOZ benchmarks and TCO blog for more info.
Additionally, you can see the “Tuning for Performance” section of the WarpStream docs for more optimization tips.
If you’re like ShareChat and use Spark for stream processing, you can make these tweaks:
By making these changes, ShareChat was able to reduce single Spark micro-batching processing times considerably. For processing throughputs of more than 220 MiB/sec, they reduced the time from 22 minutes to 50 seconds, and for processing rates of more than 200,000 records/second, they reduced the time from 6 minutes to 30 seconds.
You can grab a PDF copy of the slides from ShareChat’s presentation by clicking here. Below, you’ll find a video version of the presentation:
.svg)