We first introduced WarpStream in our blog post: "Kafka is Dead, Long Live Kafka", but to summarize: WarpStream is a Kafka protocol compatible data streaming system built directly on top of object storage. It has zero local disks, and incurs zero inter-zone bandwidth costs. Building a cost effective streaming system directly on top of object storage though is no easy feat. The most naive implementation would either result in massive object storage API costs, or require so much buffering that the system would look more like batch than streaming.
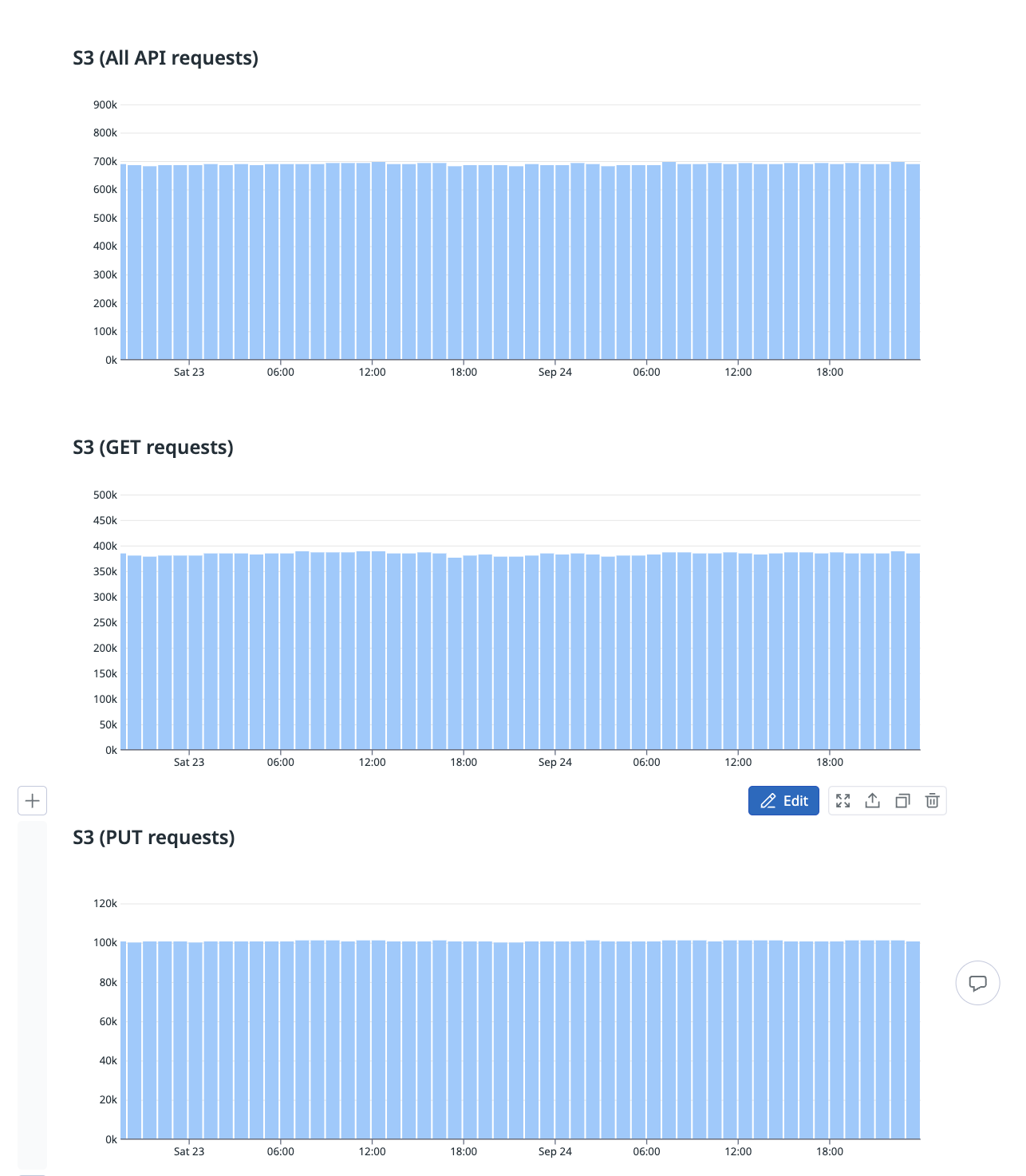
WarpStream manages to avoid both of those problems, minimizing object storage API calls while still maintaining a P99 write latency of ~400ms, all without introducing any local disks into the system. For example, the graph below shows the object storage API costs incurred by a WarpStream workload processing ~140MiB/s of writes/s along with 3 consumers. This results in a grand total of 560MiB/s of throughput through the system.
This workload would cost $641/day in inter-zone networking fees alone with a perfectly tuned Apache Kafka cluster using the follower-fetch functionality. Using WarpStream, we eliminate the $641/day in inter-zone networking fees entirely and replace them with < $40/day in object storage API costs. A pretty fair trade if you ask us!

Importantly, there is almost no relationship between the number of partitions in a WarpStream workload and the number of object storage requests that are made. For example, the graphs below depict the number of object storage API requests that one of our WarpStream clusters is making. During the depicted timeframe, we added a new workload with 1024 partitions (the previous highest running was 128). Can you tell when we enabled it? I bet not!
The magic of WarpStream’s storage engine is that it effectively decouples the relationship between the number of partitions in a workload and the number of object storage API requests that are made. Instead, the number of object storage API requests in WarpStream scales ~ linearly with throughput, but at a rate that is more than 10x cheaper than paying for inter-zone bandwidth.
Now let’s talk about the technical details of how that's possible.
Apache Kafka’s storage engine creates dedicated files per topic-partition called “segments”. New writes are persisted to the end of each topic-partition’s currently active log segment.
.png)
This works fine for Apache Kafka because it’s usually running on modern NVME SSDs that can handle a large number of individual IOPS. However, this model can’t be naively translated to object storage. Making a dedicated object storage file every 250ms would cost ~ $50/month in PUT operations alone per partition. Multiply that by 1024 partitions, and we would’ve created a problem bigger than the inter-zone networking problem we were trying to solve in the first place!
Alternatively, the problem could be solved with batching by making per-partition files every 30s, but that would also defeat the purpose. When we set out to build WarpStream, we really wanted to deliver P99 end-to-end latencies of under 1s.
We decided to take a different approach with WarpStream’s storage engine. Instead of creating dedicated files per topic-partition, each WarpStream Agent creates exactly one file every 250ms, or once it has accumulated 4MiB of writes, whichever comes first. These files contain data from all the topic-partitions for which an Agent has received data in the elapsed time period. Batches of data in these files are sorted first by topic, and then by partition.
.png)
This (almost) completely decouples WarpStream’s cost model from the number of topic-partitions entirely. Of course, this isn’t without trade-offs. Combining data from many different topic-partitions into a single file effectively decouples data from metadata. This results in a lot of external metadata being generated that has to be managed in a cost effective and scalable manner. We solved that problem too, but let’s stay focused on the storage engine for now and talk about how the read path works.
WarpStream’s read path seems like it should be straightforward. The WarpStream Agents are stateless, and all the data is in S3. Naively, it seems like each Agent should be able to just issue a GET request directly to object storage every time it receives a request to Fetch data for a specific partition. Unfortunately that would once again be extremely cost prohibitive in terms of object storage API requests.
For example, consider a workload with 1024 partitions. If every WarpStream Agent makes a new file every 250ms, then consuming this workload would require at least 1024 * (1s / 250ms) == 4096 GET requests/s (assuming an extremely well behaved client) which would cost > $4200/month, and that's just for a single consumer! Note that calculation assumes that all of the data written for a single partition in a 250ms window could be fetched from a single file. However, WarpStream takes a different approach to load-balancing than Apache Kafka does, and as a result writes for a single partition are not necessarily localized to an individual Agent. This eliminates the partition balancing problem entirely, but means data for an individual partitions is spread across a higher number of files. That means that the cost we just calculated would grow in a quadratic manner with the number of Agents, as each additional Agent would result in more files that have to be accessed by… every Agent! Not great.
Of course that calculation assumes that each Agent has to make one GET request per file per partition. We could do much better than that by instead making each Agent download each file exactly once, cache it, and then serve individual topic-partition reads out of their cache. This would be much more cost effective in terms of GET requests than the previous approach, but it would still scale poorly. Effectively, the maximum capacity of the cluster would be bound by how much data the slowest Agent could download from object storage in a given window. There is no way that would scale to massive workloads without using giant VMs, and even then we’d hit a ceiling pretty quick.
Based on those two thought experiments, we concluded that we needed a different solution that met the following criteria:
Eventually we concluded that we needed an abstraction that looked something like “distributed mmap”. In a magical world in which distributed mmap existed, we could simply map the entire S3 bucket into memory by assigning each Agent uniformly distributed portions of the address space, and then serve reads directly by letting the mmap implementation page in (and cache) blocks of data on demand.
Of course, we had to translate this neat abstraction into a concrete implementation. Luckily, this actually turned out to be pretty straightforward: First, we used a consistent hashing ring to make each Agent responsible for caching data for a subset of files. We used the ID of the file as the hash key in the consistent hashing ring to ensure good load distribution amongst all the Agents. In addition, within each Agent, we built an in-memory cache that effectively “mmaps” regions of files in object storage directly into memory. The key insight behind this in-memory cache is that it needs to be agnostic to the size of the IO requests that it's receiving. Sometimes it will need to serve a read for just a few KiB of data from a file, and other times it will need to serve multi MiB reads. Regardless, it must always load data from object storage in a cost effective manner.
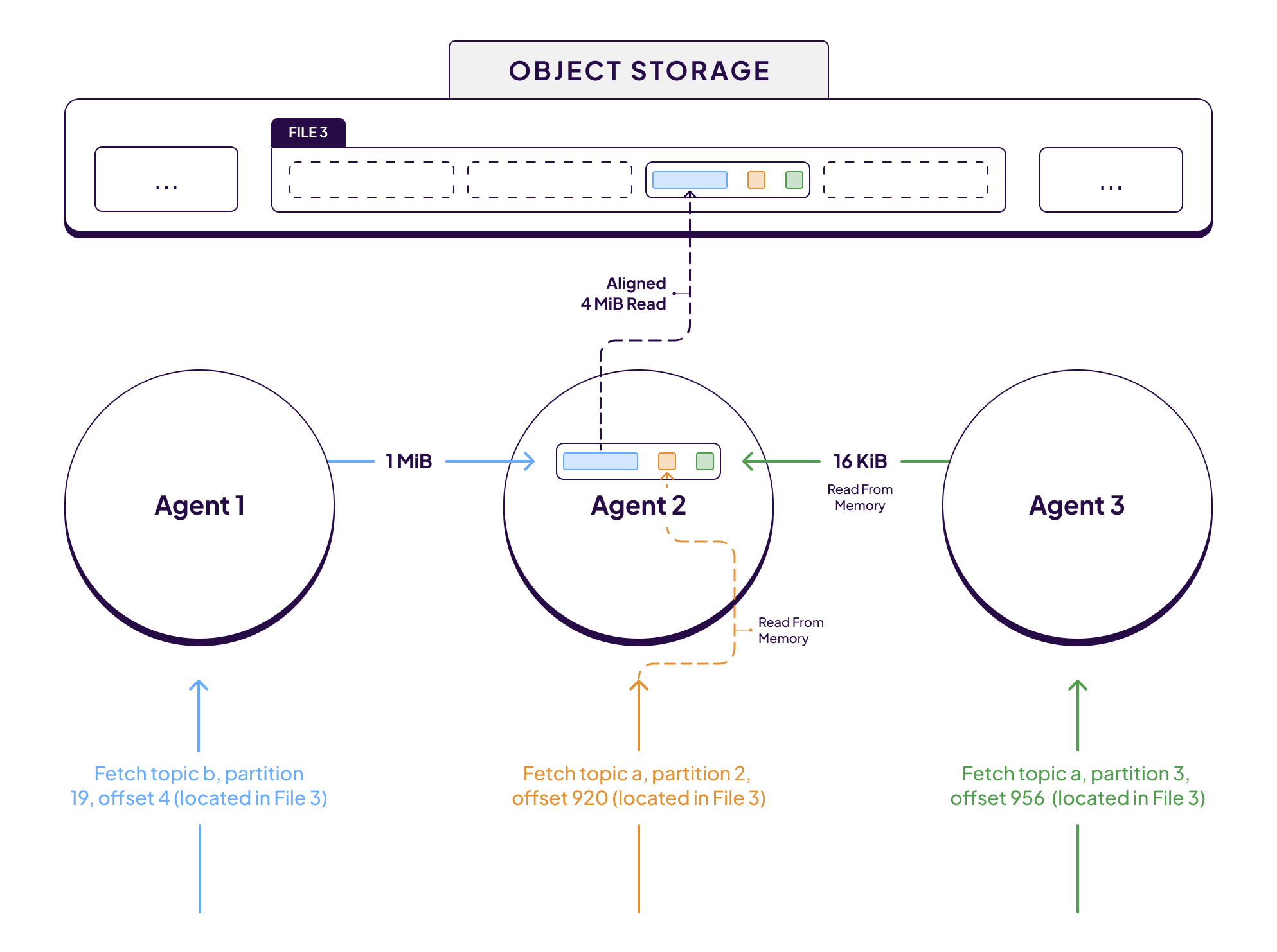
The cache accomplishes this by “paging in” data from object storage in fixed (and aligned) size chunks of 4 MiB regardless of how large the initiating IO was, and then reusing those cached 4 MiB block to serve subsequent requests.
Let’s work through an example to make this all a bit more concrete. The diagram above shows 3 concurrent Kafka fetch requests for 3 different partitions. In this particular scenario, the data for all 3 partitions happens to be located in the same 4 MiB block of data in File 3.
Each fetch request is received and processed by a different WarpStream Agent. However, since the data required to serve each fetch request is located in File 3, sub-fetch requests are issued to the Agent responsible for File 3 in the consistent hashing ring, in this case that’s Agent 2. Initially, Agent 2 will not have File 3 in memory because the file was just created by Agent 1. However, as soon as Agent 2 receives a sub-fetch for data in File 3, it will begin paging in 4 MiB chunks of that file on demand.
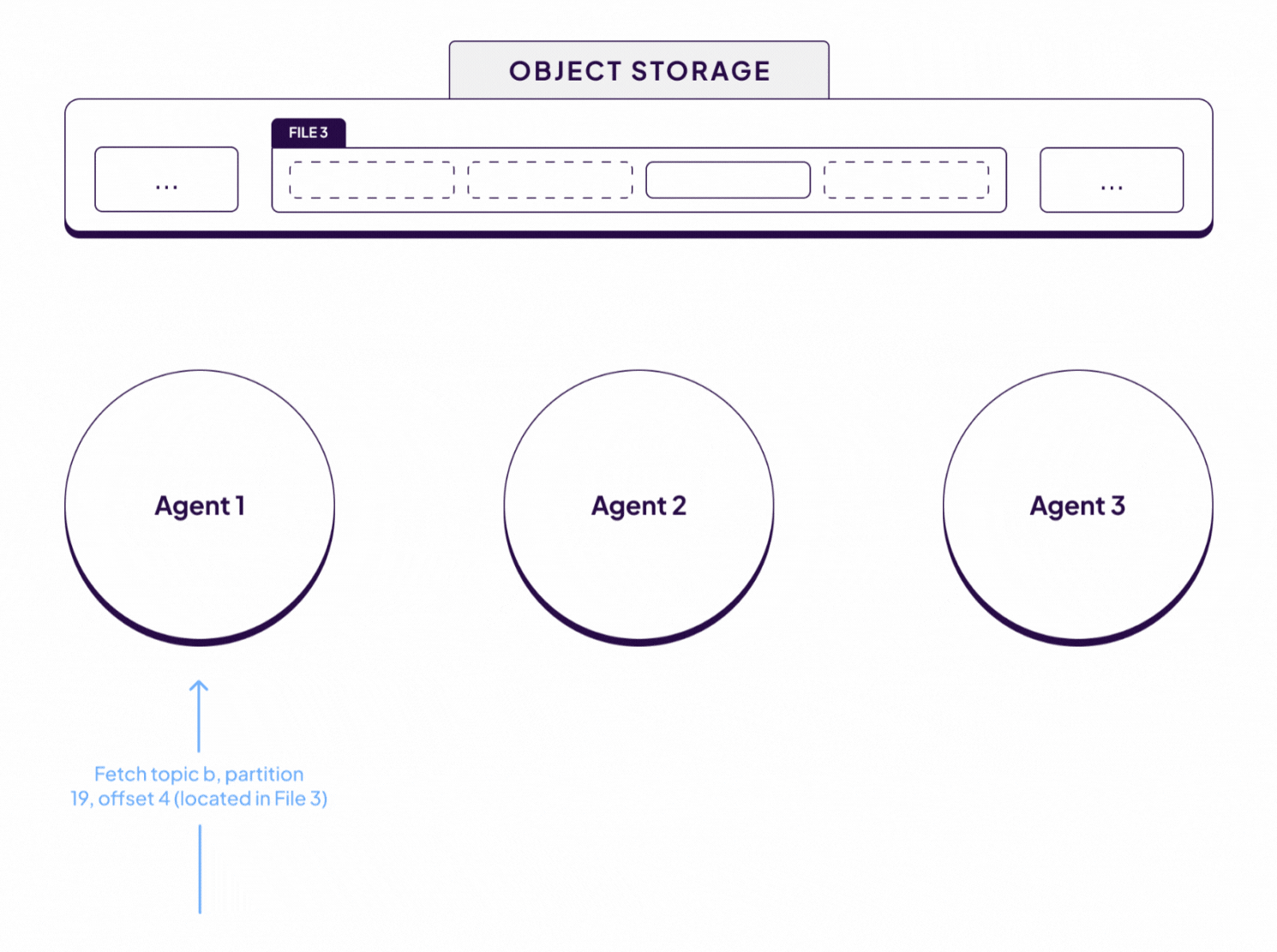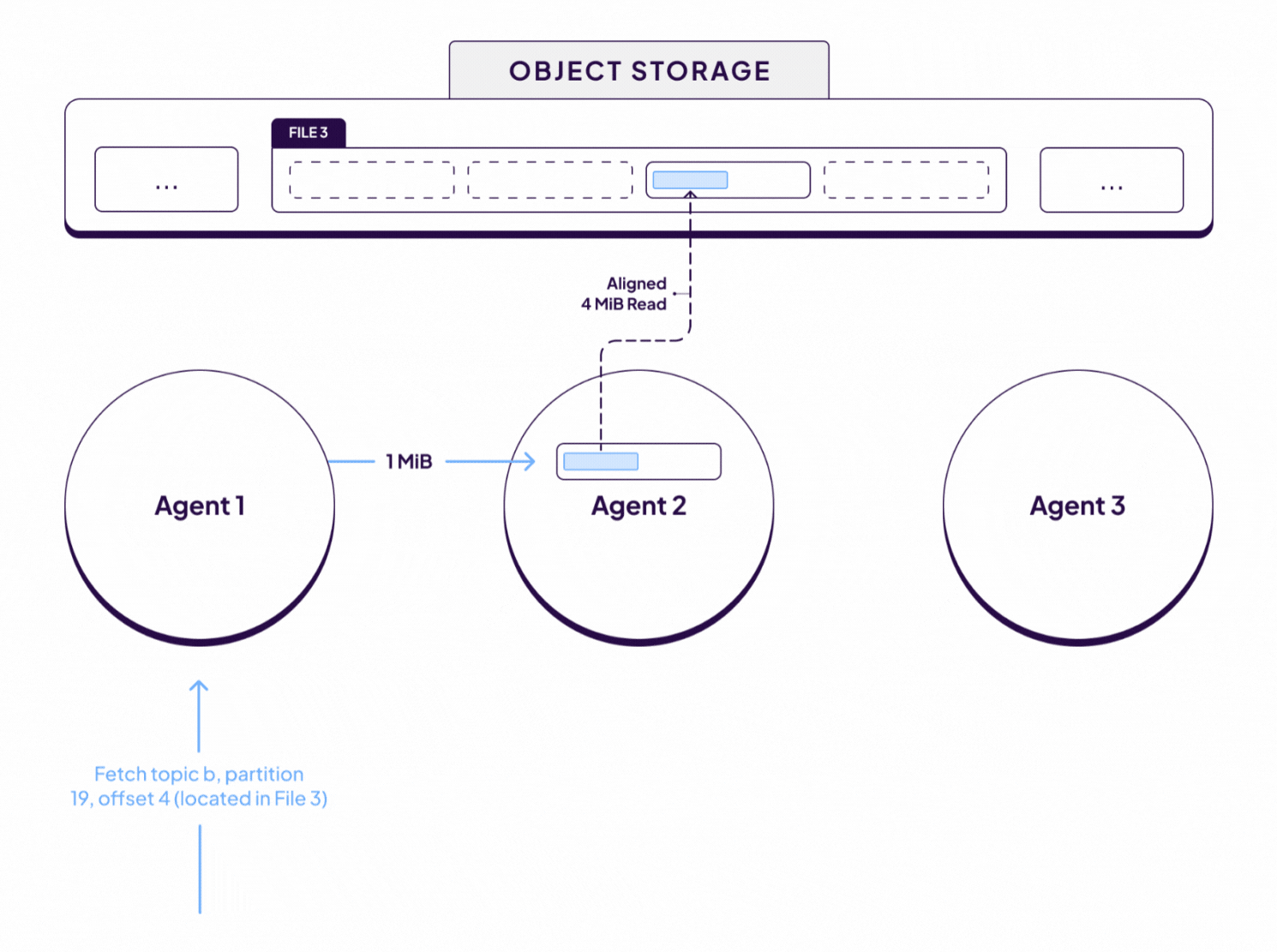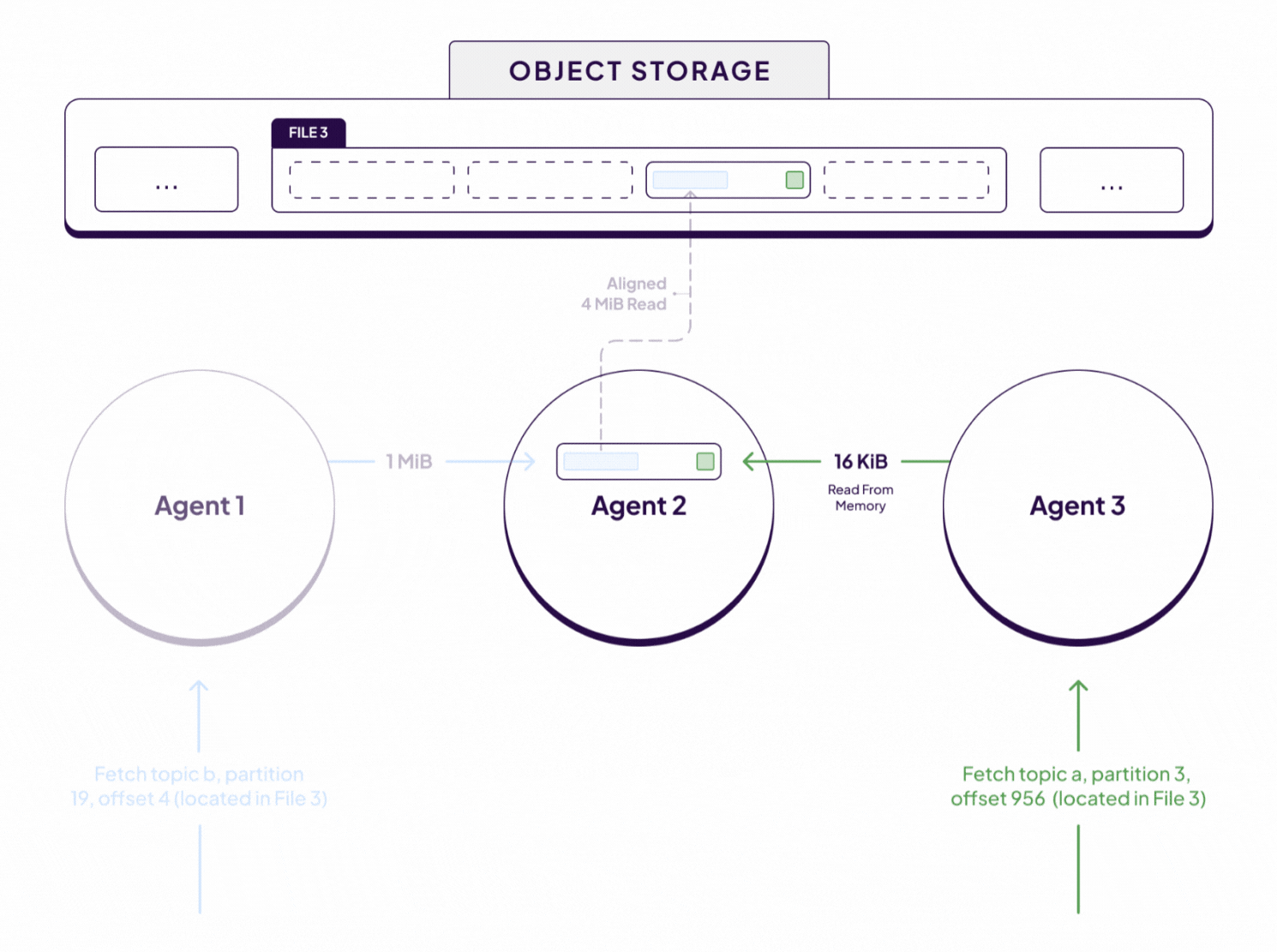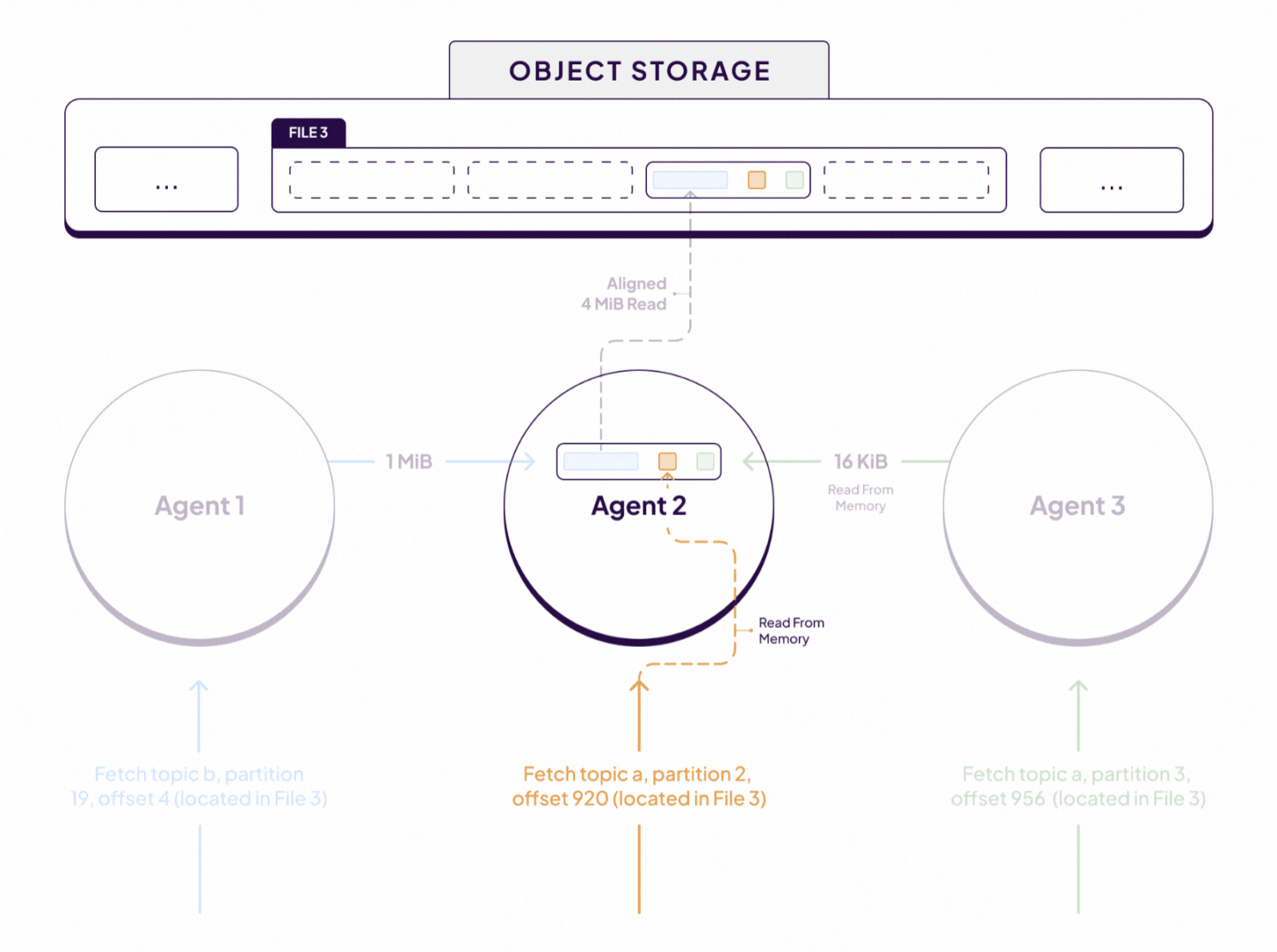
Subsequently, Agent 2 receives sub-fetch requests for data from 2 other partitions whose data is also located in that same 4MiB chunk that was just fetched from object storage. In that case, those fetches will be served immediately from memory with no additional object storage requests.
As a result of all this, we converted what would have been 3 object storage requests into 1. That may not seem like much, but it generalizes to workloads of all shapes and sizes. For example, with this approach a Kafka topic with 1024 partitions can be processed with the same number of object store GET requests as a topic with 1 partition.
Note that the diagrams above are intentionally “sparse” for illustrative purposes. However, the most common scenario where all the data being produced is also actively being consumed by 1 or more consumer groups results in an extremely “dense” and efficient io workload. Every 4MiB chunk of every newly created file is downloaded once, and only once, by a specific Agent and the “over fetching” results in virtually zero waste as it's almost guaranteed that every byte will eventually be read by one of the active consumers. Those of you coming from the database world may recognize this technique as a form of scan sharing.
Another neat feature of directing all reads for a given file to a single Agent in the cluster is that it eliminates the thundering herd problem: each Agent will deduplicate concurrent requests to object storage for the same tuple of <file_id, 4_mib_chunk>.
Keep in mind that this entire process is performed once per availability zone, so in practice every 4 MiB chunk of every file has to be downloaded 3 times, once per availability zone. However, even with this requirement, the net result is still more than 10x cheaper than paying for inter-zone bandwidth.
Another way to think about all of this is that we use object storage as the storage layer and the network layer to replicate data between availability zones, and then we use our distributed mmap implementation to ensure data is downloaded once and only once per availability zone.
If you’ve been following very carefully, you may have one final burning question in your head: what happens if most of the consumers are keeping up with the live workload, but a few consumers are lagging and reading old or historical data? An individual lagging consumer processing historical data will experience nothing but cache misses almost by definition. In addition, the “dense” distributed mmap IO pattern we just discussed is only efficient and cost effective when the 4 MiB object storage fetches can be shared amongst reads for many different partitions, by consumers who are all “caught up” and processing the “live edge” of data.
.png)
In the worst case scenario, every "unaligned" lagging consumer requires just as many GET requests to consume a single partition (1 GET request per file) as is required to consume all of the partitions in the non-lagging case where all of the consumers are processing roughly the same set of newly created files. In other words, a single lagging consumer processing a single partition could double the number of GET requests. Not great!
The solution to this problem is simple: the WarpStream Agents actively compact the small files created at ingestion time into much larger files which have significantly higher amounts of data per-partition in a given file. These compactions are really fast and result in huge reductions in read amplification. As a result, the distributed mmap cache is really only required for the live edge of data. Any data that is more than a few seconds old has already been compacted into larger files with massively improved data locality, and thus a massively reduced number of GET requests required to read data for individual partitions. We could serve reads for compacted data directly from object storage, but in practice we run all those requests through the distributed mmap implementation as well because the deduplication and caching benefits it provides are still useful.
Compacting the data may sound expensive, but in practice it's highly efficient since it only needs to happen once, can be done with large amounts of fan in, and processes files in a completely streaming fashion. Specifically, the streaming algorithm ensures that compaction require little memory, and only results in one additional GET request per input file (no matter how large it is). Compaction has a lot of other benefits too. For example, it provides the WarpStream storage engine with the opportunity to merge small batches of topic-partition data into larger batches, which can dramatically improve compression for some workloads.
We’ll explain more about how compaction works in future blog posts, but in the meantime you can subscribe to our updates at the bottom of this package, or come join our Slack channel, we’d love to hear from you!
