Robinhood is a financial services company that allows electronic trading of stocks, cryptocurrency, automated portfolio management and investing, and more. With over 14 million monthly active users and over 10 terabytes of data processed per day, its data scale and needs are massive.
Robinhood software engineers Ethan Chen and Renan Rueda presented a talk at Current New Orleans 2025 (see the appendix for slides, a video of their talk, and before-and-after cost-reduction charts) about their transition from Kafka to WarpStream for their logging needs, which we’ve reproduced below.
Logs at Robinhood fall into two categories: application-related logs and observability pipelines, which are powered by Vector. Prior to WarpStream, these were produced and consumed by Kafka.
The decision to migrate was driven by the highly cyclical nature of Robinhood's platform activity, which is directly tied to U.S. stock market hours. There’s a consistent pattern where market hours result in higher workloads. External factors can vary the load throughout the day and sudden spikes are not unusual. Nights and weekends are usually low traffic times.
%20(1).png)
Traditional Kafka cloud deployments that rely on provisioned storage like EBS volumes lack the ability to scale up and down automatically during low- and high-traffic times, leading to substantial compute (since EC2 instances must be provisioned for EBS) and storage waste.
“If we have something that is elastic, it would save us a big amount of money by scaling down when we don’t have that much traffic,” said Rueda.
WarpStream’s S3-compatible diskless architecture combined with its ability to auto-scale made it a perfect fit for these logging workloads, but what about latency?
“Logging is a perfect candidate,” noted Chen. “Latency is not super sensitive.”
The logging system's complexity necessitated a phased migration to ensure minimal disruption, no duplicate logs, and no impact on the log-viewing experience.
Before WarpStream, the logging setup was:
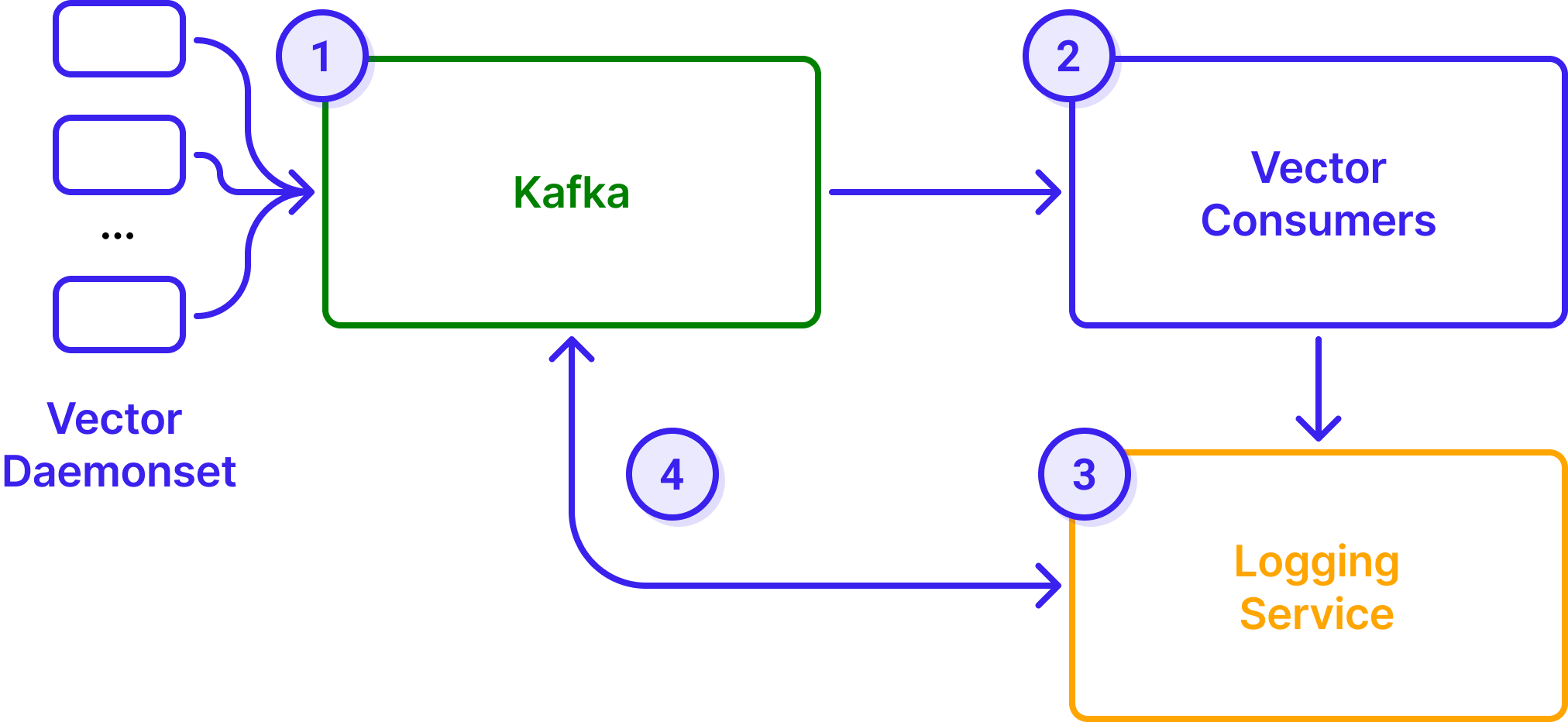
To migrate, the Robinhood team broke the monolithic Kafka cluster into two WarpStream clusters – one for the logging service and one for the vector daemonset, and split the migration into two distinct phases: one for the Kafka cluster that powers their logging service, and one for the Kafka cluster that powers their vector daemonset.
For the logging service migration, Robinhood’s logging Kafka setup is “all or nothing.” They couldn’t move everything over bit by bit – it had to be done all at once. They wanted as little disruption or impact as possible (at most a few minutes), so they:
For the Vector logging shipping, it was a more gradual migration, and involved two steps:
Now, Robinhood leverages this kind of logging architecture, allowing them more flexibility:
%20(1).png)
Below, you can see how Robinhood set up its WarpStream cluster.
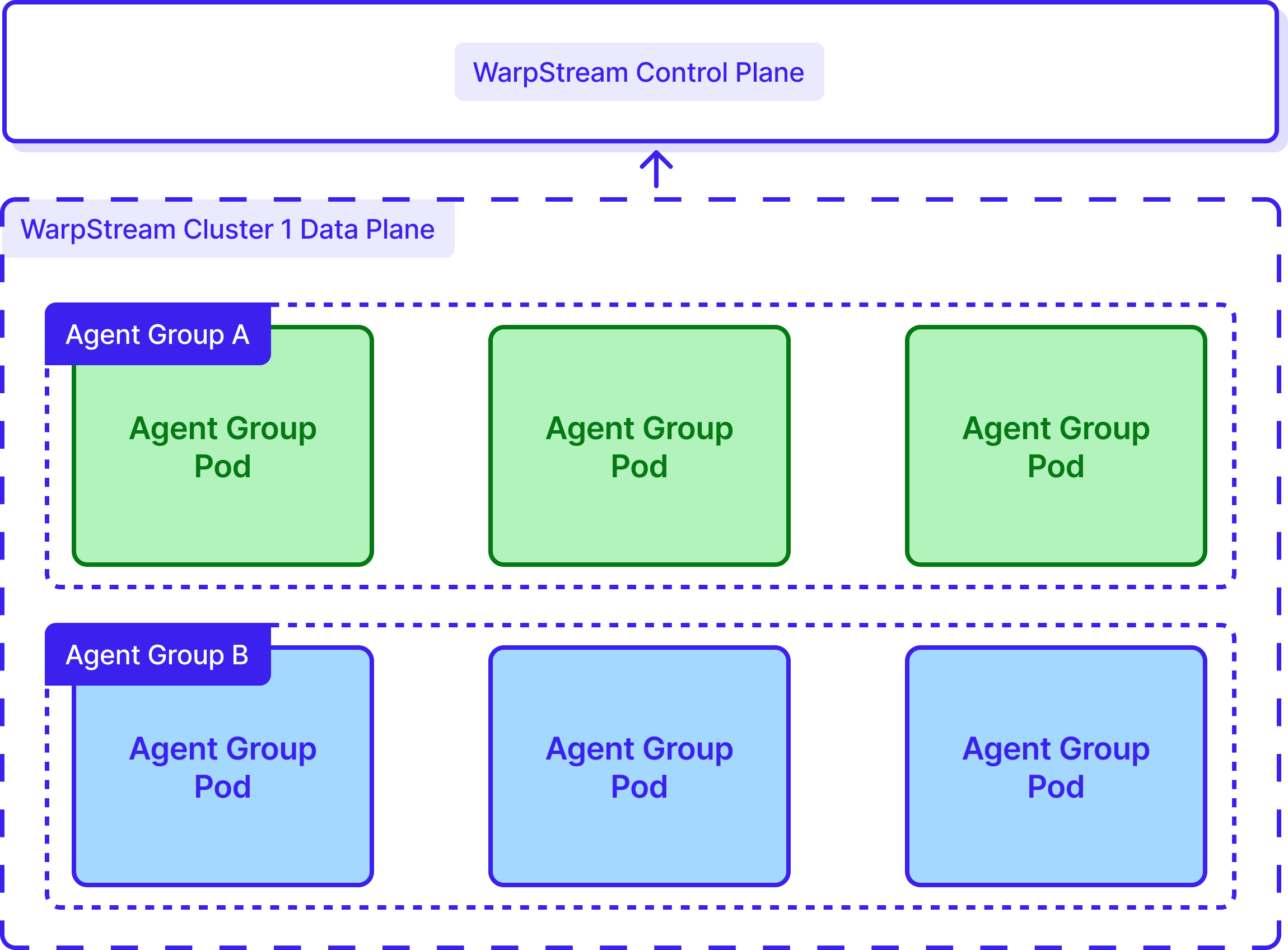
The team designed their deployment to maximize isolation, configuration flexibility, and efficient multi-account operation by using Agent Groups. This allowed them to:
This architecture also unlocked another major win: it simplified multi-account infrastructure. Robinhood granted permissions to read and write from a central WarpStream S3 bucket and then put their Agent Groups in different VPCs. An application talks to one Agent Group to ship logs to S3, and another Agent Group consumes them, eliminating the need for complex inter-VPC networking like VPC peering or AWS PrivateLink setups.
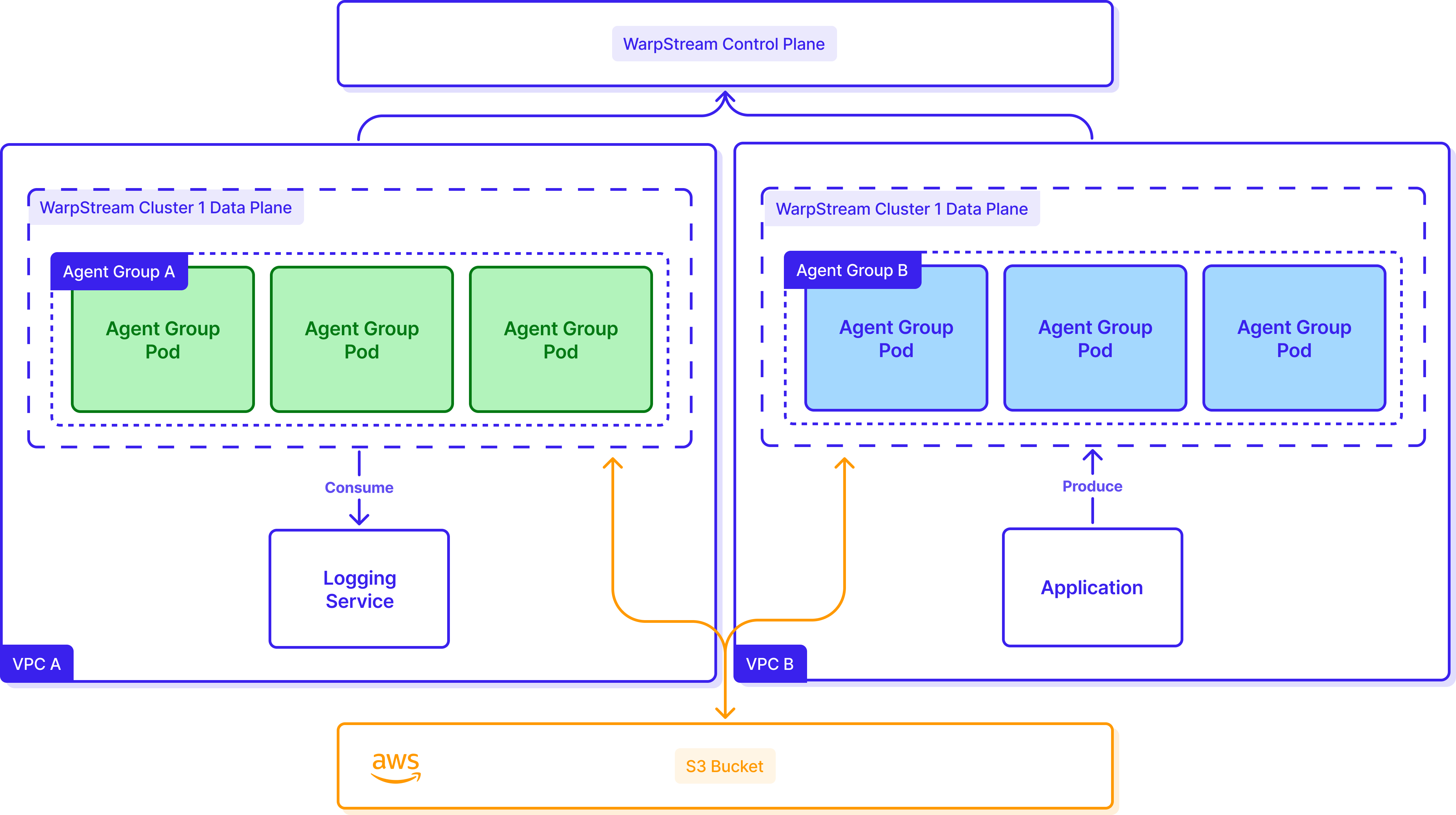
WarpStream is optimized for reduced costs and simplified operations out of the box. Every deployment of WarpStream can be further tuned based on business needs.
WarpStream’s standard instance recommendation is one core per 4 GiB of RAM, which Robinhood followed. They also leveraged:
Compared to their prior Kafka-powered logging setup, WarpStream massively simplified operations by:
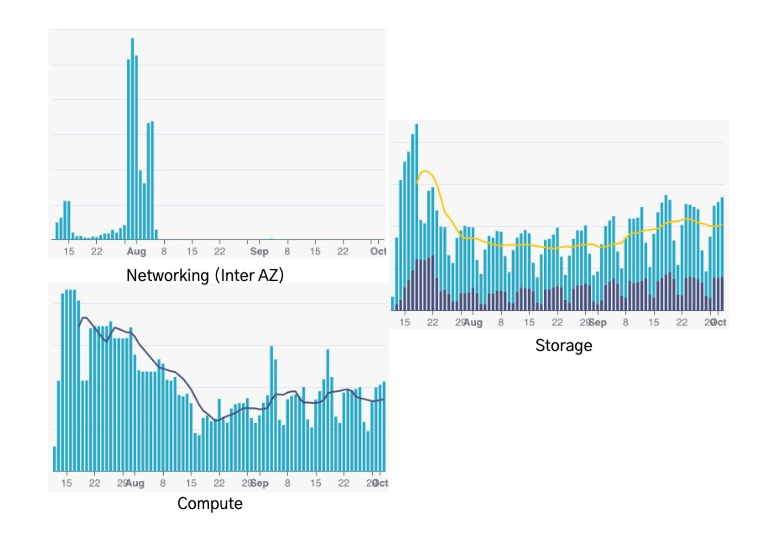
And how did that translate into more networking, compute, and storage efficiency, and cost savings vs. Kafka? Overall, WarpStream saved Robinhood 45% compared to Kafka. This efficiency stemmed from eliminating inter-AZ networking fees entirely, reducing compute costs by 36%, and reducing storage costs by 13%.
You can grab a PDF copy of the slides from Robinhood's presentation by clicking here. Below, you’ll find a video version of the presentation: