MCP Server
The WarpStream MCP Server connects AI assistants like Claude and Cursor directly to your clusters. Query logs, inspect Diagnostics, and investigate ACL events without leaving your IDE. Just ask questions and let the AI handle the rest. Learn more via the annoucement blog and our docs.
Events
WarpStream Events capture Agent logs, ACL decisions, and pipeline execution logs. They allow you to ditch multiple tools and get built-in observability without any additional infrastructure. Learn more about them in our blog post and the docs.
Audit Logs
Kafka itself provides limited built-in auditing. You can piece together some information from broker logs, but those logs are unstructured, scattered across brokers, and not designed for long-term retention or compliance. WarpStream Audit Logs give you a complete, structured record of every authentication action, authorization decision, and platform operation across your WarpStream clusters.
Lightning Topics + Ripcord Mode (50ms p99)
We're excited to launch Lightning Topics and Ripcord Mode. Lightning Topics use delayed sequencing to achieve 33ms median produce latency with S3 Express One Zone — a 70% reduction. Ripcord Mode lets Agents continue processing writes during Control Plane outages.
WarpStream Tableflow Generally Available
After working with our early access partners to add features and functionality, we're excited to announce that WarpStream Tableflow is now generally available. Learn more about Tableflow via its product page and docs.
.png)
ACL Shadowing
ACLs are needed for security, but enabling them in production carries risks. WarpStream ACL Shadowing evaluates ACLs before enforcing them, so engineers can identify and fix issues safely.
.png)
Dark Mode
WarpStream now includes a fully functional dark mode. 🪄
Multiple Tableflow Updates
We released a number of updates to Tableflow, including Protobuf schema support, inline transformations, an Iceberg REST catalog, a Snowflake integration, and data retention and TTL support.
Protobuf Support for WarpStream BYOC Schema Registry
WarpStream's BYOC Schema Registry already supports JSON and Avro and now includes support for Protobuf, with complete compatibility with Confluent's Schema Registry.
WarpStream Tableflow
Tableflow is an Iceberg-native database that materializes tables from any Kafka topic and automates ingestion, compaction, and maintenance. It features our zero ops, zero access model, and works with any Kafka-compatible source (Open-Source Kafka, MSK, Confluent Cloud, WarpStream, etc), and can run in any cloud or even on-premise, allowing simultaneous ingestion from multiple different Kafka clusters to centralize your data in a single lake.
Our blog goes over why existing approaches like Apache Spark, "Zero Copy Kafka" or tiered storage, and connector-based products are incomplete solutions.
Single Partition Prefetching
Single Partition Prefetching is now enabled by default. It is a useful feature for workloads that primarily consume data from individual partitions as it minimizes the overhead and latency associated with object storage.
By proactively fetching and caching data for a specific partition before the consumer explicitly requests the next batch, it masks the inherent latency of object storage GET requests, leading to much higher throughput and a smoother, more real-time experience for single-threaded or low-concurrency consumers.
Multi-Region Clusters
WarpStream Multi-Region Clusters guarantee zero data loss (RPO=0) out of the box with zero additional operational overhead, as well as multi-region consensus and automatic failover handling.
Our announcement blog goes over how we developed this feature and why customers would want to leverage these types of clusters.
Datadog Integration
Datadog has released an official WarpStream integration. All the Warpstream Agent metrics can be ingested by Datadog so you can query them, as well as set up monitoring and dashboards.

Schema Linking
WarpStream Schema Linking continuously migrates any Confluent-compatible schema registry into a WarpStream BYOC Schema Registry. WarpStream now has a comprehensive Data Governance suite to handle schema needs, stretching from schema validation to schema registry and now migration and replication.
Diagnostics
Diagnostics continuously analyzes your clusters to identify potential problems, cost inefficiencies, and ways to make things better. It looks at the health and cost of your cluster and gives detailed explanations on how to fix and improve them.
Support for Kafka Transactions
We added support for Kafka transactions and in our detailed engineering blog, we break down how they work in Apache Kafka and our unique implementation.
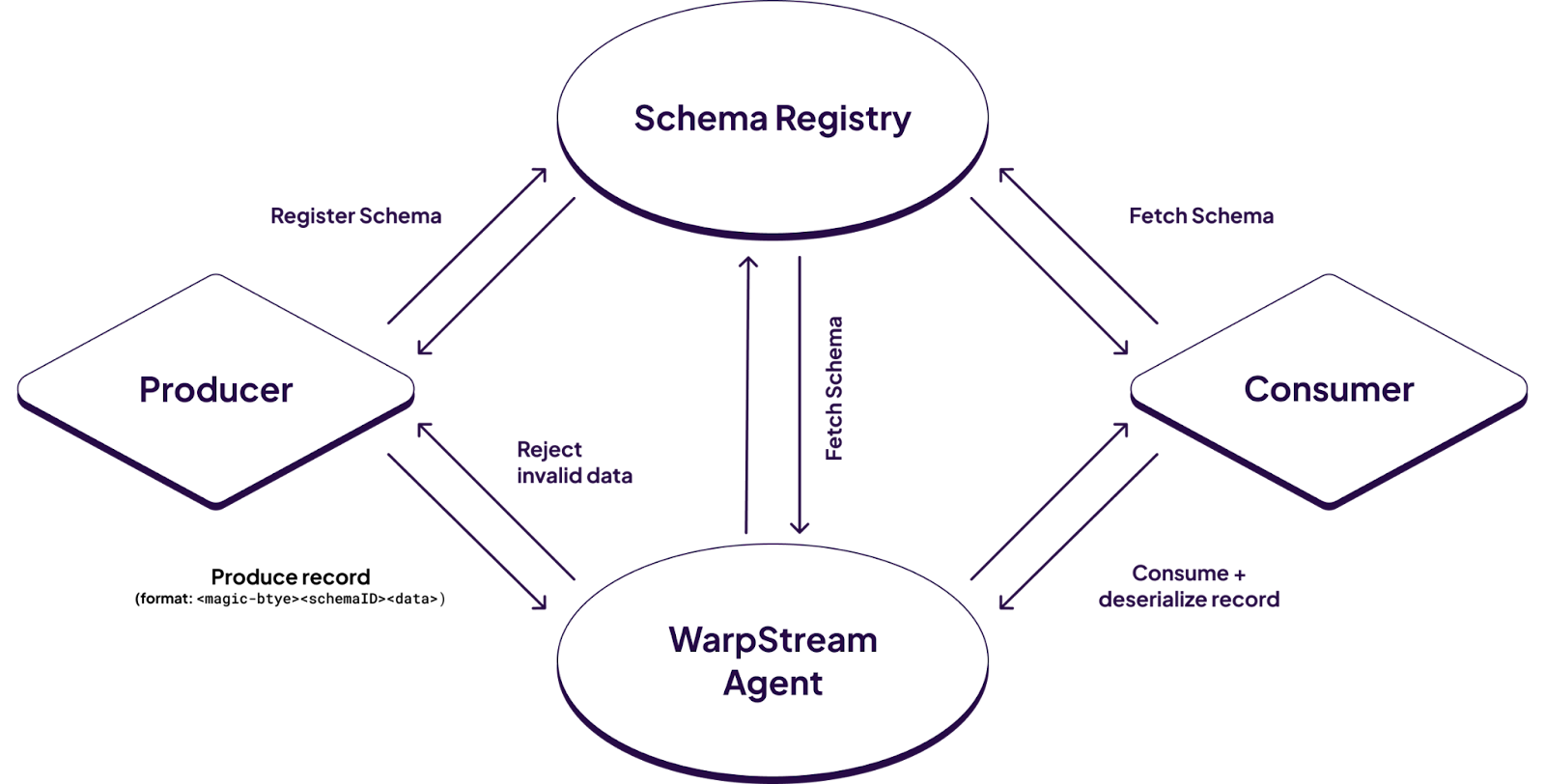
WarpStream BYOC Schema Registry
WarpStream's BYOC Schema Registry is a schema registry implementation that is API-compatible with Confluent's Schema Registry, but deployed using WarpStream's BYOC deployment model and architected with WarpStream's signature data plane / control plane split.
All your schemas sit securely in your own cloud environment and object storage buckets, with WarpStream responsible for scaling the metadata (schema ID assignments, concurrency control, etc).
Orbit
Orbit is a tool which creates identical, inexpensive, scaleable, and secure continuous replicas of Kafka clusters. It is built into WarpStream and works without any user intervention to create WarpStream replicas of any Apache Kafka-compatible source cluster like open source Apache Kafka, WarpStream, Amazon MSK, etc.
Records copied by Orbit are offset preserving. Every single record will have the same offset in the destination cluster as it had in the source cluster, including any offset gaps.
Schema Validation with AWS Glue Schema Registry
We noticed that not all our customers use a Kafka-specific Schema Registry, so we added support for a popular alternative: AWS Glue.
Confluent Acquires WarpStream
WarpStream is going from being a private, VC-backed company and has been acquired by the leader in Kafka data streaming, Confluent.
In our blog, we note that the WarpStream product and website will continue to exist and Confluent's backing provides more resources for use to be even more ambitious with our product roadmap and deliver new features even faster than before.
Polling Logic Enhancements
This update refines how the WarpStream handles "long-polling" fetch requests when no new data is available for a set of topic-partitions. By optimizing the wait-and-retry logic, it reduces unnecessary CPU cycles and network overhead, ensuring that consumers receive new data as quickly as possible once it arrives without overwhelming the agent.
Schema Validation
WarpStream Agents can connect to any Kafka-compatible Schema Registry and validate that records conform to the provided schema. WarpStream Schema Validation validates not only that the schema ID encoded in a given record matches the schema ID in the Schema Registry, but also that the record actually conforms with the provided schema.
Native Time Lag Measurement
Measuring consumer group lag in Kafka using offsets isn't always the best approach. Time lag makes it much easier to monitor and troubleshoot consumer groups. Time lag measurement is built directly into WarpStream – no third-party tooling is needed.
Metadata Topics Cache
Metadata Topics Cache reduces the latency of Kafka Metadata requests from several hundred milliseconds down to just tens of microseconds by serving them from a local cache.
This improvement is critical for high-scale environments where many clients or tools (like Kafka UI or monitoring agents) frequently poll for metadata, preventing "thundering herd" issues and improving overall client compatibility.
Managed Data Pipelines
We took streaming processing support via Bento a step further by releasing Managed Data Pipelines, which provides a fully-managed SaaS user experience for Bento, without sacrificing any of the cost benefits, data sovereignty, or deployment flexibility of the BYOC deployment model.
In our blog, we go over features like a user interface in the WarpStream Console for creating and editing pipelines; the ability to pause and resume pipelines; version control and branching; automatic handling of SASL authentication and AZ-aware routing; and control over concurrency. Bento has an extensive list of over 150 input, output, and processor integrations.
Stream Processing Support
As part of our continued goal of being 100% stateless and keeping infrastructure footprints small, we wanted to add stream processing support, but avoid stateful systems.
We achieved that goal by bundling stream processing support directly in the WarpStream Agent and made it simple to configure via a YAML file.
WarpStream Generally Available (GA)
In our "The Original Sin of Cloud Infrastructure" blog, we review the inherent problems with cloud economics for Kafka and how "lift and shift" BYOC attempts fail, and how WarpStream BYOC is Kafka-compatible data-streaming infrastructure purpose built for the cloud.
WarpStream has moved from EA to GA and we raised $20 million in funding from Amplify Partners and Greylock Partners.
S3 Express One Zone Support
S3 Express One Zone is a tier of AWS S3 that provides much lower latency for writes and reads, but only stores the data in a single availability zone. The WarpStream Agents have native support for S3 Express and can use it to store newly written data. Combined with a reduced batch timeout, S3 express can reduce the P99 latency of Produce requests to less than 150ms.
We wrote a blog that was published on Amazon's AWS Storage Blog noting that WarpStream's customers can achieve 3-4x lower end-to-end latency (from producer to consumer), while also leveraging a stateless architecture backed by object storage.
In April 2025, Amazon announced a 85% price reduction in S3 Express One Zone, so we released a blog about the TCO for WarpStream customers that use S3 Express One Zone and a benchmark, which showed 3x lower latency than using S3 standard.
Agent Groups
Agent Groups are distinct sets of Agents that all belong to the same logical cluster that use a shared object storage bucket as the storage and network layer. Groups enable a single logical cluster to be split into many different "groups" that are isolated at the network / service discovery layer.
You can leverage Agent Groups to: isolate analytical workloads from transactional ones; flex a single, logical cluster across multiple VPCs, regions, or cloud providers without the need for complex VPC peering; and split workloads at the hardware level, while still sharing data sets.
Agent Groups are a great way to prevent "noisy neighbors" or resource contention.
WarpStream Goes Public and Announces Early Access (EA)
We published of first blog titled, "Kafka is Dead, Long Live Kafka" to announce WarpStream Bring Your Own Cloud (BYOC), noting that WarpStream is 80+% cheaper than running open-source or managed Kafka in the cloud, and made operationally simpler thanks its stateless foundation, which uses S3-compatible object storage. This makes WarpStream the first zero disk or diskless Kafka solution in market.
The announcement garnered a lot of attention, netting a front-page placement on Hacker News.