If you’re on a Data or Data Platforms team, you’ve probably already seen the productivity boost that comes from pulling business logic out of various ETL pipelines, queries, and scripts and centralizing it in SQL in a clean, version-controlled git repo managed by dbt. The engine that unlocked this approach is the analytical data warehouse: typically Snowflake or BigQuery.
Materialize is the operational complement to the analytical warehouse. It’s the engine that precipitates the same shift for your business’s operational logic. Everything scattered around in scripts, microservices, SaaS tools, can be centralized in SQL in a clean, version-controlled git repo managed by dbt. With a streaming computation model instead of batch, your data is always up to date, always consistent, and always immediately accessible, so you can build real-time automation, engaging customer experiences, and new operational data products that drive value for your business.
This all sounds great in theory, but to compute results continuously, you're going to need to load data continuously. That's where teams often look to the industry-standard approach for anything streaming: Apache Kafka.
The industry-standard approach for anything streaming is to make use of a durable log like Apache Kafka.
However, Apache Kafka is an extremely stateful system that co-locates compute and storage. That means that your organization will have to develop in-house expertise on how to manage the Apache Kafka clusters, including the brokers and their local disks, as well as a strongly consistent metadata store like ZooKeeper or KRaft.
Before you can even consider deploying Kafka into your infrastructure, you’ll first have to learn about:
All of this infrastructure has to be managed with extreme care and diligence to avoid loss of availability or data durability. In practice, self hosted Kafka clusters require a dedicated team of experts and significant amounts of custom tooling before even basic operations like node replacements and scaling clusters can be performed safely and reliably.
That’s where WarpStream comes in.
WarpStream is an Apache Kafka® protocol compatible data streaming platform that runs directly on top of any commodity object store (AWS S3, GCP GCS, Azure Blob Storage, etc). It incurs zero inter-AZ bandwidth costs, has no local disks to manage, and can run completely within your VPC.
WarpStream is usually significantly more cost effective than Apache Kafka, however, even more importantly, WarpStream dramatically reduces the operational burden of incorporating data streaming into your organization.
WarpStream implements the Apache Kafka protocol which means it looks and behaves just like a traditional Kafka cluster, but under the hood it has a completely different implementation that separates compute from storage and offloads all of the tricky scaling and maintenance operations to cloud provider object storage like S3.
Instead of Kafka brokers, WarpStream has “Agents”. Agents are stateless Go binaries (no JVM!) that speak the Kafka protocol, but unlike a traditional Kafka broker, any WarpStream Agent can act as the “leader” for any topic, commit offsets for any consumer group, or act as the coordinator for the cluster. No Agent is special, so auto-scaling them based on CPU-usage is trivial. This means that adopting WarpStream in your organization is as simple as deploying a stateless container like Nginx into your infrastructure; there are virtually no operations to manage!
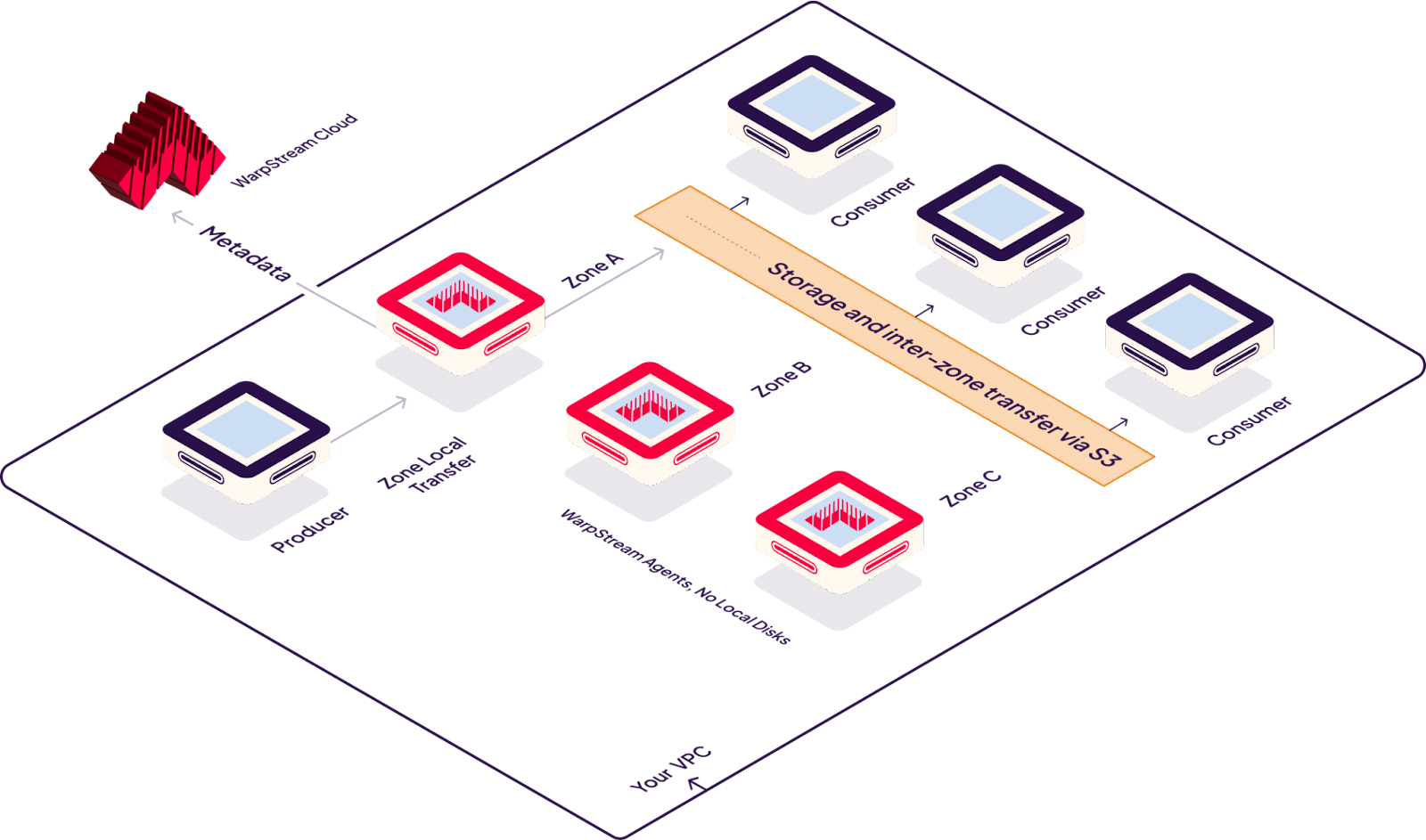
Of course, WarpStream requires a consensus layer for correct operations, just like Apache Kafka does. However, In addition to separating compute from storage, WarpStream takes things one step further by separating data from metadata. This enables WarpStream’s “Bring Your Own Cloud” deployment model where the WarpStream agents are deployed into your VPC, and store all of their data in an S3 bucket in your cloud account, but metadata management is offloaded to “Virtual Cluster”s in WarpStream’s cloud so you don’t have to manage it.
We’ll demonstrate how to integrate WarpStream and Materialize by running the WarpStream Agents on the cloud platform Fly.io, and then producing synthetic click stream data that Materialize will consume and transform to generate streaming SQL aggregations.
Prerequisites
After signing up for WarpStream, use the follow these instructions to deploy your first cluster to Fly.io.
Next, follow these instructions for creating a new set of credentials to connect to your WarpStream cluster. If everything goes smoothly, you should be able to use your newly created credentials to connect to your WarpStream cluster running in Fly.io and test the connection using any Kafka client. In this example, we’ll use the WarpStream CLI which has an embedded Kafka client:
Now that WarpStream is up and running, let’s create a topic called: materialize_click_streams.
Next, let’s produce a few records. The WarpStream CLI uses ,, as a delimiter between JSON records.
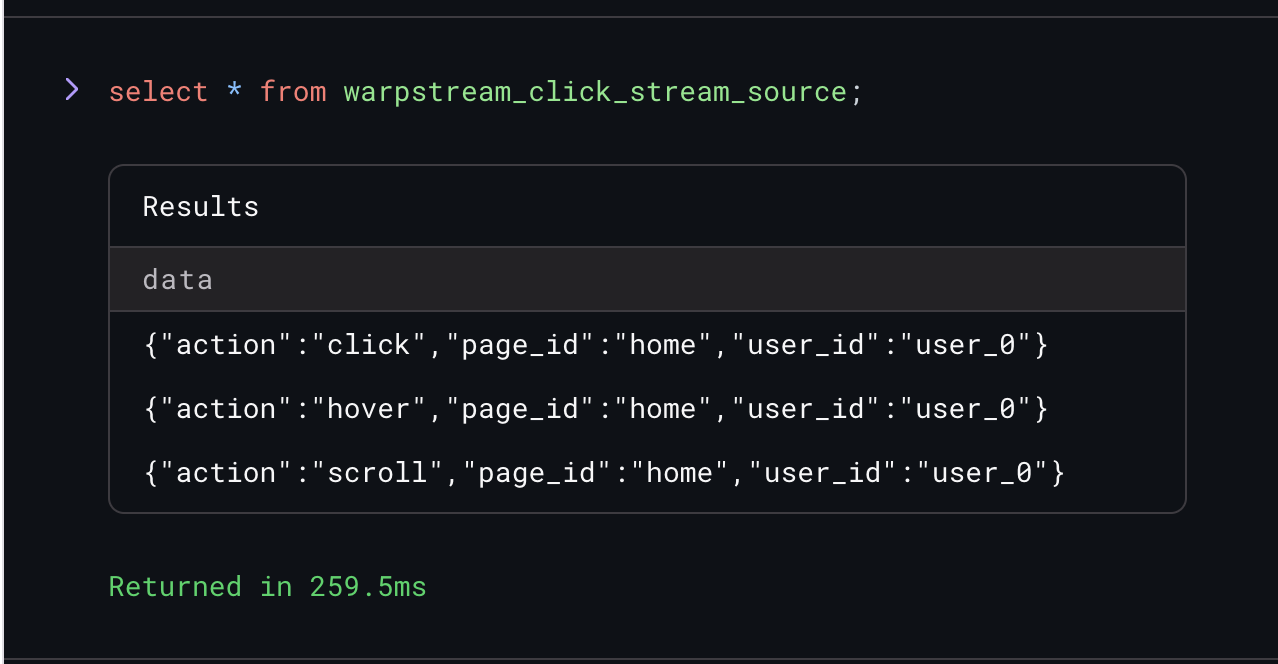
Once the topic has some data in it, we can switch over to Materialize and start writing some SQL. First, we need to tell Materialize how to start ingesting data from our WarpStream cluster:
Materialize will begin automatically ingesting data from the WarpStream Kafka cluster once the source is created. We can verify that by running a simple SQL query:
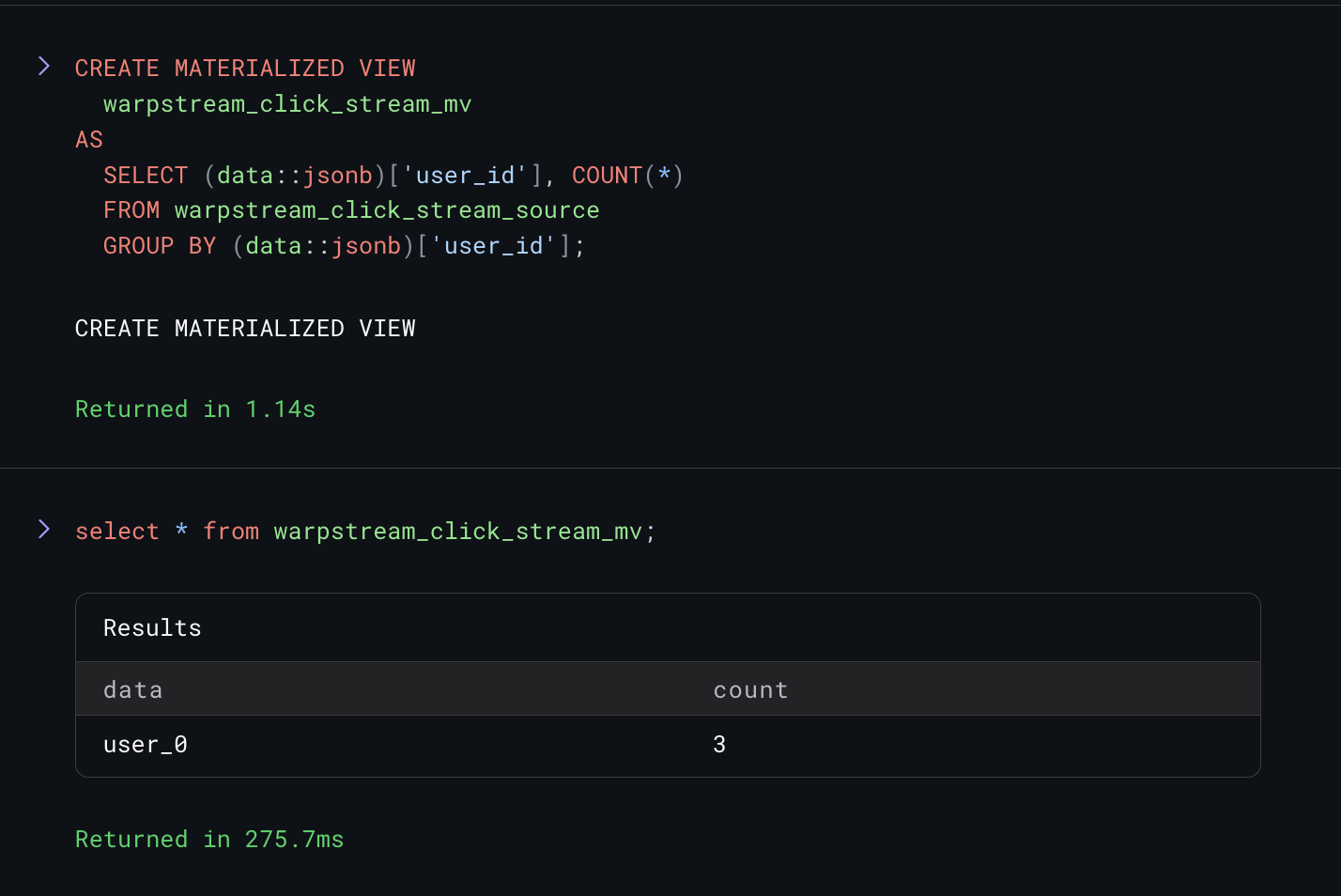
Now that data is streaming in, lets create a materialized view to do some streaming SQL aggregations. In this case, we’ll create a materialized view that counts the number of interactions every user has in real time:
Finally, let's write one more record to Kafka and watch our materialized view update in real time.
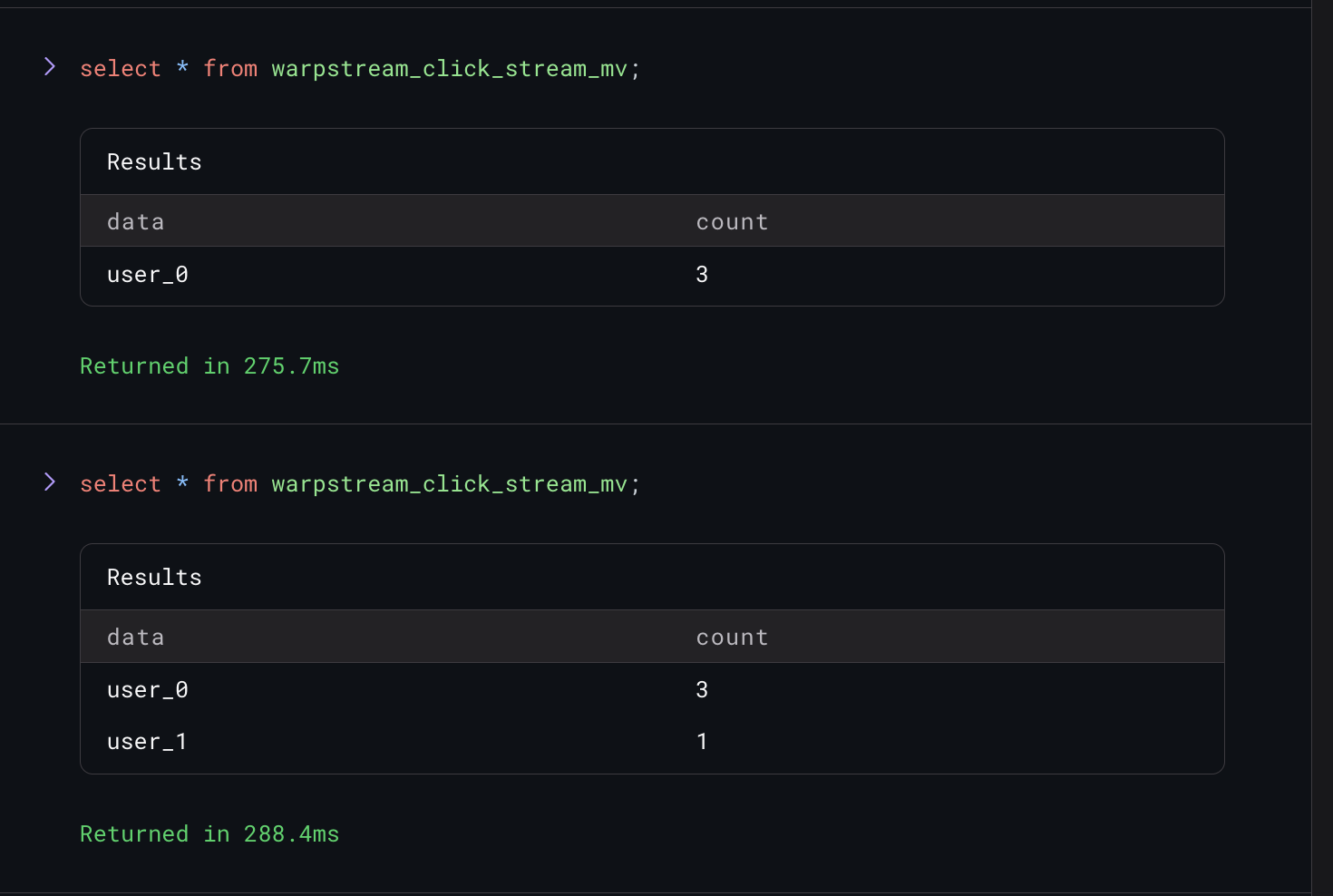
And just like that we have a materialized view we can query at any time that will be automatically maintained by Materialize in real time.
WarpStream is in developer preview, but you can sign up now and try it for free completely self serve. Come join us in our community Slack channel!
To get going with Materialize, head over to Materialize.com and register for a free trial.
